图像基础
读取图像
cv2.read(image file, parms) 读取路径的图片
| prams | value | description |
|---|---|---|
cv2.IMREAD_COLOR |
1 | 读入彩色图像,忽略图像透明度 |
cv2.IMREAD_GRAYSCALE |
0 | 以灰度模式读入图像 |
cv2.IMREAD_UNCHANGED |
-1 | 读入一幅图像,包括图像的alpha通道 |
显示图像
使用函数cv2.imshow() 显示图像。窗口会自动调整为图像大小。第一 个参数是窗口的名字,其次才是我们的图像。你可以创建多个窗口,只要你喜欢,但是必须给他们不同的名字。
cv2.waitKey()是一个键盘绑定函数。需要指出的是它的时间尺度是毫秒级。函数等待特定的几毫秒,看是否有键盘输入。特定的几毫秒之内,如果按下任意键,这个函数会返回按键的 ASCII 码值,程序将会继续运行。如果没有键盘输入,返回值为 -1,如果设置这个函数的参数为0,那它将会无限期的等待键盘输入。它也可以被用来检测特定键是否被按下,例如按键 a 是否 被按下。
cv2.destroyAllWindows() 可以轻易删除任何我们建立的窗口。如果你想删除特定的窗口可以使用 cv2.destroyWindow(),在括号内输入你想删除的窗口名。
建议:一种特殊的情况是先创建窗口再加载图像。这种情况下可以决定窗口是否可以调整大小。使用的函数是 cv2.namedWindow()。初始设定函数标签是 cv2.WINDOW_AUTOSIZE。如果把标签改 成cv2.WINDOW_NORMAL,就可以调整窗口大小了。当图像维度太大或者要添加轨迹条时,调整窗口大小将会很有用。
保存图像
使用函数 cv2.imwrite() 来保存一个图像。首先需要一个文件名,之后才 是你要保存的图像。
1 | import cv2 |
2 | import numpy |
3 | img = cv2.imread("material/5.jpg",-1) #读取路径下的图像 |
4 | cv2.namedWindow("image",cv2.WINDOW_NORMAL) #先建立一个窗口,并设置标签为WINDOW_NORMAL以调整窗口大小 |
5 | cv2.imshow("image", img) |
6 | cv2.waitKey(0) |
7 | cv2.destroyAllWindows() |
8 | cv2.imwrite('messigray.png',img) #将图片以PNG格式保存 |
总结
下面的程序将会加载一个灰度图,显示图片,按下$’s’$键保存后退出,或者 按下 $ESC$ 键退出不保存。
1 | import numpy as np |
2 | import cv2 |
3 | |
4 | img = cv2.imread('messi5.jpg',0) |
5 | cv2.imshow('image',img) |
6 | k = cv2.waitKey(0) |
7 | if k == 27: # wait for ESC key to exit |
8 | cv2.destroyAllWindows() |
9 | elif k == ord('s'): # wait for 's' key to save and exit |
10 | cv2.imwrite('messigray.png',img) |
11 | cv2.destroyAllWindows() |
警告: 64 位系统需要将 k = cv2.waitKey(0) 这行改成 k = cv2.waitKey(0)&0xFF。
使用matplotlib
1 | import numpy as np |
2 | import cv2 |
3 | from matplotlib import pyplot as plt |
4 | #读取图片 |
5 | img = cv2.imread('material/5.jpg',-1) |
6 | #将图片由GBR模式转换回RGB模式 |
7 | b,g,r = cv2.split(img) |
8 | img2 = cv2.merge([r,g,b]) |
9 | #用matplotlib输出 |
10 | plt.imshow(img2, cmap = 'gray', interpolation = 'bicubic') |
11 | plt.xticks([]), plt.yticks([]) # to hide tick values on X and Y axis |
12 | plt.show() |
注意: 彩色图像使用 $OpenCV$ 加载时是 $BGR$ 模式。但是 $Matplotib$ 是 $RGB$ 模式。所以彩色图像如果已经被 $OpenCV$ 读取,那它将不会被 $Matplotib$ 正确显示。
视频基础
摄像头捕获视频
下面代码使用摄像头来捕获一段视频,并把它转换成灰度视频显示出来。
为了获取视频,你应该创建一个 $VideoCapture$ 对象。他的参数可以是设备的索引号,或者是一个视频文件。设备索引号就是在指定要使用的摄像头。 一般的笔记本电脑都有内置摄像头。所以参数就是$0$。你可以通过设置成 $1$或者其他的来选择别的摄像头。之后就可以一帧一帧的捕获视频了。但是最后,别忘了停止捕获视频。
1 | import numpy as np |
2 | import cv2 |
3 | |
4 | #创建VideoCapture对象 |
5 | cap = cv2.VideoCapture(0) |
6 | |
7 | while(True): |
8 | # Capture frame-by-frame |
9 | ret, frame = cap.read() |
10 | # Our operations on the frame come here |
11 | gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) |
12 | # Display the resulting frame |
13 | cv2.imshow('frame',gray) |
14 | if cv2.waitKey(1) & 0xFF == ord('q'): |
15 | break |
16 | # When everything done, release the capture |
17 | cap.release() |
18 | cv2.destroyAllWindows() |
cap.read()返回一个布尔值($True/False$)。如果帧读取的是正确的, 就是 True。所以最后可以通过检查他的返回值来查看视频文件是否已经到 了结尾。
有时 $cap$ 可能不能成功初始化摄像头设备。这种情况下上面的代码会报错。你可以使用 cap.isOpened()来检查是否成功初始化了。如果返回值是 $True$,那就没有问题。否则就要使用函数 cap.open()。
可以使用函数 cap.get(propId) 来获得视频的一些参数信息。这里 $propId$ 可以是 $0$ 到 $18$ 之间的任何整数。每一个数代表视频的一个属性(见下表),其中的一些值可以使用 cap.set(propId,value) 来修改,$value$ 就是想要设置成的新值。 例如,可以使用 cap.get(3) 和 cap.get(4) 来查看每一帧的宽和高。默认情况下得到的值是 $640480$。但是可以使用 ret=cap.set(3,320) 和 ret=cap.set(4,240) 来把宽和高改成 $320240$。
| pram | define |
|---|---|
cv2.VideoCapture.get(0) |
视频文件的当前位置(播放)以毫秒为单位 |
cv2.VideoCapture.get(1) |
基于以0开始的被捕获或解码的帧索引 |
cv2.VideoCapture.get(2) |
视频文件的相对位置(播放):0=电影开始,1=影片的结尾。 |
cv2.VideoCapture.get(3) |
在视频流的帧的宽度 |
cv2.VideoCapture.get(4) |
在视频流的帧的高度 |
cv2.VideoCapture.get(5) |
帧速率 |
cv2.VideoCapture.get(6) |
编解码的4字-字符代码 |
cv2.VideoCapture.get(7) |
视频文件中的帧数 |
cv2.VideoCapture.get(8) |
返回对象的格式 |
cv2.VideoCapture.get(9) |
返回后端特定的值,该值指示当前捕获模式 |
cv2.VideoCapture.get(10) |
图像的亮度(仅适用于照相机) |
cv2.VideoCapture.get(11) |
图像的对比度(仅适用于照相机) |
cv2.VideoCapture.get(12) |
图像的饱和度(仅适用于照相机) |
cv2.VideoCapture.get(13) |
色调图像(仅适用于照相机) |
cv2.VideoCapture.get(14) |
图像增益(仅适用于照相机)(Gain在摄影中表示白平衡提升) |
cv2.VideoCapture.get(15) |
曝光(仅适用于照相机) |
cv2.VideoCapture.get(16) |
指示是否应将图像转换为7$RGB$布尔标志 |
cv2.VideoCapture.get(17) |
× 暂时不支持 |
cv2.VideoCapture.get(18) |
立体摄像机的矫正标注(目前只有$DC1394 v.2.x$后端支持这个功能) |
从文件中播放视频
与从摄像头中捕获一样,只需要把设备索引号改成视频文件的名字。在播放每一帧时,使用cv2.waitKey() 设置适当的持续时间。如果设置的太低视频就会播放的非常快,如果设置的太高就会播放的很慢(可以使用这种方法控制视频的播放速度)。通常情况下 25 毫秒就可以了。
保存视频
要创建一个 $VideoWriter$ 的对象。我们应该确定一个输出文件 的名字。接下来指定 $FourCC$ 编码(下面会介绍)。播放频率和帧的大小也都需要确定。最后一个是 $isColor$ 标签。如果是 $True$,每一帧就是彩色图,否则就是灰度图。 $FourCC$ 就是一个 4 字节码,用来确定视频的编码格式。可用的编码列表 可以从fourcc.org查到。这是平台依赖的。下面这些编码器是比较常用的。
- In Fedora:
DIVX, XVID, MJPG, X264, WMV1, WMV2. (XVID is more preferable. MJPG results in high size video. X264 gives very small size video) - In Windows:
DIVX (More to be tested and added) - In OSX :
(I don’t have access to OSX. Can some one fill this?)
$FourCC$ 码以下面的格式传给程序,以 $MJPG$ 为例: cv2.cv.FOURCC('M','J','P','G') 或者 cv2.cv.FOURCC(\*'MJPG')。
下面的代码是从摄像头中捕获视频,沿竖直方向旋转每一帧并保存它。
1 | import numpy as np |
2 | import cv2 |
3 | |
4 | cap = cv2.VideoCapture(0) |
5 | # Define the codec and create VideoWriter object |
6 | fourcc = cv2.VideoWriter_fourcc(*'DIVX') |
7 | out = cv2.VideoWriter('e.avi',fourcc, 20.0, (640,480)) |
8 | |
9 | while(cap.isOpened()): |
10 | ret, frame = cap.read() |
11 | if ret==True: |
12 | frame = cv2.flip(frame,1) #0为沿水平方向旋转,任意正数为沿竖直方向旋转,任意负数为同时 |
13 | |
14 | # write the flipped frame |
15 | out.write(frame) |
16 | |
17 | cv2.imshow('frame',frame) |
18 | if cv2.waitKey(1) & 0xFF == ord('q'): |
19 | break |
20 | else: |
21 | break |
22 | # Release everything if job is finished |
23 | cap.release() |
24 | out.release() |
25 | cv2.destroyAllWindows() |
OpenCV绘图函数
这些绘图函数需要设置下面这些参数:
- $img:$你想要绘制图形的那幅图像。
- $color:$形状的颜色。以 $RGB$ 为例,需要传入一个元组,例如:$(255,0,0)$ 代表蓝色。对于灰度图只需要传入灰度值。
- $thickness:$线条的粗细。如果给一个闭合图形设置为 $-1$,那么这个图形就会被填充。默认值是 $1$。
- $linetype:$线条的类型,$8$连接,抗锯齿等。默认情况是 $8$ 连接。
cv2.LINE_AA为抗锯齿,这样看起来会非常平滑。
画线
要画一条线,只需要告诉函数这条线的起点和终点。下面代码会画一条从左上方到右下角的蓝色线段。
1 | import numpy as np |
2 | import cv2 |
3 | |
4 | # Create a black image |
5 | img = np.zeros((512,512,3),np.uint8) |
6 | # Draw a diagonal blue line with thickness of 5 px |
7 | cv2.line(img,(0,0),(511,511),(255,0,0),5) |
8 | # Show the image |
9 | cv2.imshow("img",img) |
10 | cv2.waitKey(0) |
11 | cv2.destroyAllWindows() |
画矩形
要画一个矩形,你需要告诉函数的左上角顶点和右下角顶点的坐标。下面的代码会在图像的右上角画一个绿色的矩形。
1 | cv2.rectangle(img,(384,0),(510,128),(0,255,0),3) |
画圆
要画圆的话,只需要指定圆形的中心点坐标和半径大小。我们在上面的矩形中画一个圆。
1 | cv2.circle(img,(447,63),63,(0,0,255),-1) |
画椭圆
画椭圆比较复杂,我们要多输入几个参数。一个参数是中心点的位置坐标。 下一个参数是长轴和短轴的长度。椭圆沿顺时针旋转的角度。椭圆弧沿顺时针方向起始的角度和结束角度,如果是 $0$ 和 $360$,就是整个椭圆。查看 cv2.ellipse() 可以得到更多信息。下面的例子是在图片的中心绘制半个白色椭圆。
1 | cv2.ellipse(img,(256,256),(100,50),0,0,180,(255,255,255),-1) |
画多边形
画多边形可以使用cv2.polylines(),需要指点每个顶点的坐标。用这些点的坐标构建一个大小等于$行数12$的数组,行数就是点的数目。这个数组的数据类型必须为 int32。 这里画一个黄色的具有四个顶点的多边形。
1 | pts=np.array([[10,5],[20,30],[70,20],[50,10]], np.int32) |
2 | pts=pts.reshape((-1,1,2)) |
3 | cv2.polylines(img,[pts],True,(0,255,255),3) |
注意: 如果第三个参数是 False,我们得到的多边形是不闭合的(首尾不相连)。
cv2.polylines() 可以被用来画很多条线。只需要把想要画的线放在一 个列表中,将这个列表传给函数就可以了。每条线都会被独立绘制。这会比用 cv2.line() 一条一条的绘制要快一些。
在图片上添加文字
要在图片上绘制文字需要设置下列参数:
- 你要绘制的文字
- 你要绘制的位置
- 字体类型(通过查看
cv2.putText()的文档找到支持的字体) - 字体的大小
- 文字的一般属性如颜色,粗细,线条的类型等。为了更好看一点推荐使用
linetype=cv2.LINE_AA。
以下代码在图像上绘制OpenCV
1 | font = cv2.FONT_HERSHEY_SIMPLEX |
2 | cv2.putText(img,"OpenCV",(10,500),font,4,(255,255,0),2) |
最终效果
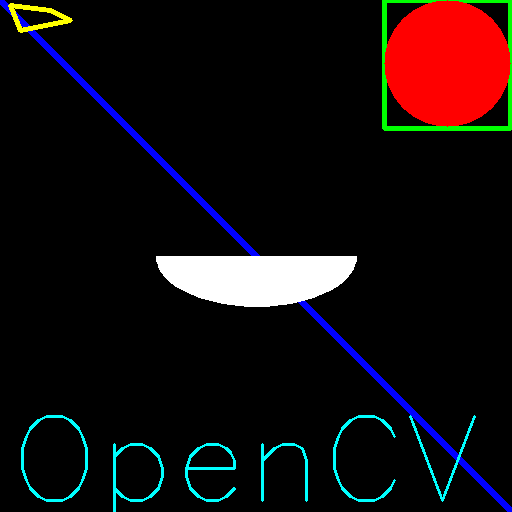
鼠标当画笔
鼠标事件 :cv2.setMouseCallback()
| events | 参数 | 对应操作 |
|---|---|---|
cv2_EVENT_MOUSEMOVE |
0 | 滑动 |
cv2_EVENT_LBUTTONDOWN |
1 | 左键点击 |
cv2_EVENT_RBUTTONDOWN |
2 | 右键点击 |
cv2_EVENT_MBUTTONDOWN |
3 | 中间点击 |
cv2_EVENT_LBUTTONUP |
4 | 左键释放 |
cv2_EVENT_RBUTTONUP |
5 | 右键释放 |
cv2_EVENT_MBUTTONUP |
6 | 中间释放 |
cv2_EVENT_LBUTTONDBLCLK |
7 | 左键双击 |
cv2_EVENT_RBUTTONDBLCLK |
8 | 右键双击 |
cv2_EVENT_MBUTTONDBLCLK |
9 | 中间双击 |
| flags | 参数 | 对应操作 |
|---|---|---|
cv2_EVENT_FLAG_LBUTTON |
1 | 左键拖拽 |
cv2_EVENT_FLAG_RBUTTON |
2 | 右键拖拽 |
cv2_EVENT_FLAG_MBUTTON |
4 | 中间拖拽 |
cv2_EVENT_FLAG_CTRLKEY |
8 | (8~15)按$Ctrl$不放事件 |
cv2_EVENT_FLAG_SHIFTKEY |
16 | (16~31)按$Shift$不放事件 |
cv2_EVENT_FLAG_ALTKEY |
32 | (32~39)按$Alt$不放事件 |
下面代码实现在图片双击左键画一个圆。
1 | import cv2 |
2 | import numpy as np |
3 | #mouse callback function |
4 | def draw_circle(event,x,y,flags,param): |
5 | if event==cv2.EVENT_LBUTTONDBLCLK: |
6 | cv2.circle(img,(x,y),100,(255,0,0),-1) |
7 | # 创建图像与窗口并将窗口与回调函数绑定 |
8 | img=np.zeros((512,512,3),np.uint8) |
9 | cv2.namedWindow('image') |
10 | cv2.setMouseCallback('image',draw_circle) |
11 | while(1): |
12 | cv2.imshow('image',img) |
13 | if cv2.waitKey(20)&0xFF==27: |
14 | break |
15 | cv2.destroyAllWindows() |
下面代码完成的任务是根据选择的模式在拖动鼠标时绘制矩形或者是圆圈(就像画图程序中一样)。所以回调函数包含两部分,一部分画矩形,一部分画圆圈。这是一个典型的例子帮助我们更好理解与构建人机交互式程序,比如物体跟踪,图像分割等。
1 | import cv2 |
2 | import numpy as np |
3 | # 当鼠标按下时变为 True |
4 | drawing=False |
5 | # 如果 mode 为 true 绘制矩形。按下'm' 变成绘制曲线。 |
6 | mode=True |
7 | ix,iy=-1,-1 |
8 | # 创建回调函数 |
9 | def draw_circle(event,x,y,flags,param): |
10 | global ix,iy,drawing,mode |
11 | # 当按下左键是返回起始位置坐标 |
12 | if event==cv2.EVENT_LBUTTONDOWN: |
13 | drawing=True |
14 | ix,iy=x,y |
15 | # 当鼠标左键按下并移动是绘制图形。event 可以查看移动,flag 查看是否按下 |
16 | elif event==cv2.EVENT_MOUSEMOVE and flags==cv2.EVENT_FLAG_LBUTTON: |
17 | if drawing==True: |
18 | if mode==True: |
19 | cv2.rectangle(img,(ix,iy),(x,y),(0,255,0),-1) |
20 | else: |
21 | # 绘制圆圈,小圆点连在一起就成了线,3 代表了笔画的粗细 |
22 | cv2.circle(img,(x,y),3,(0,0,255),-1) |
23 | # 下面注释掉的代码是起始点为圆心,起点到终点为半径的 |
24 | # r=int(np.sqrt((x-ix)**2+(y-iy)**2)) |
25 | # cv2.circle(img,(x,y),r,(0,0,255),-1) |
26 | # 当鼠标松开停止绘画。 |
27 | elif event==cv2.EVENT_LBUTTONUP: |
28 | drawing==False |
29 | # if mode==True: |
30 | # cv2.rectangle(img,(ix,iy),(x,y),(0,255,0),-1) |
31 | # else: |
32 | # cv2.circle(img,(x,y),5,(0,0,255),-1) |
33 | |
34 | img=np.zeros((512,512,3),np.uint8) |
35 | cv2.namedWindow('image') |
36 | cv2.setMouseCallback('image',draw_circle) |
37 | while(1): |
38 | cv2.imshow('image',img) |
39 | k=cv2.waitKey(1)&0xFF |
40 | if k==ord('m'): |
41 | mode=not mode |
42 | elif k==27: |
43 | break |
滑动条做调色板
现在我们来创建一个简单的程序:通过调节滑动条来设定画板颜色。我们要创建一个窗口来显示显色,还有三个滑动条来设置 B,G,R 的颜色。当滑动滚动条时窗口的颜色也会发生相应改变。默认情况下窗口的起始颜色为黑。
cv2.getTrackbarPos() 函数的第一个参数是滑动条的名字,第二个参数是滑动条被放置窗口的名字,第三个参数是滑动条的默认位置。第四个参数是滑动条的最大值,第五个参数是回调函数,每次滑动条的滑动都会调用回调函数。回调函数通常都会含有一个默认参数,就是滑动条的位置。在本例中这个函数不用做任何事情,我们只需要 pass 就可以了。 滑动条的另外一个重要应用就是用作转换按钮。默认情况下 OpenCV 本 身不带有按钮函数。所以我们使用滑动条来代替。在我们的程序中,我们要创建一个转换按钮,只有当装换按钮指向 ON 时,滑动条的滑动才有用,否则窗口都是黑的。
1 | import cv2 |
2 | import numpy as np |
3 | def nothing(x): |
4 | pass |
5 | # 创建一副黑色图像 |
6 | img=np.zeros((300,512,3),np.uint8) |
7 | cv2.namedWindow('image') |
8 | cv2.createTrackbar('R','image',0,255,nothing) |
9 | cv2.createTrackbar('G','image',0,255,nothing) |
10 | cv2.createTrackbar('B','image',0,255,nothing) |
11 | switch='0:OFF\n1:ON' |
12 | cv2.createTrackbar(switch,'image',0,1,nothing) |
13 | while(1): |
14 | cv2.imshow('image',img) |
15 | k=cv2.waitKey(1)&0xFF |
16 | if k==27: |
17 | break |
18 | r=cv2.getTrackbarPos('R','image') |
19 | g=cv2.getTrackbarPos('G','image') |
20 | b=cv2.getTrackbarPos('B','image') |
21 | s=cv2.getTrackbarPos(switch,'image') |
22 | if s==0: |
23 | img[:]=0 |
24 | else: |
25 | img[:]=[b,g,r] |
26 | cv2.destroyAllWindows() |
下面例程实现了创建一个画板,可以自选各种颜色的画笔绘制线条和矩形。
1 | import cv2 |
2 | import numpy as np |
3 | def nothing(x): |
4 | pass |
5 | # 当鼠标按下时变为 True |
6 | drawing=False |
7 | # 如果 mode 为 true 绘制矩形。按下'm' 变成绘制曲线。 |
8 | mode=True |
9 | ix,iy=-1,-1 |
10 | # 创建回调函数 |
11 | def draw_circle(event,x,y,flags,param): |
12 | r=cv2.getTrackbarPos('R','image') |
13 | g=cv2.getTrackbarPos('G','image') |
14 | b=cv2.getTrackbarPos('B','image') |
15 | color=(b,g,r) |
16 | global ix,iy,drawing,mode |
17 | # 当按下左键是返回起始位置坐标 |
18 | if event==cv2.EVENT_LBUTTONDOWN: |
19 | drawing=True |
20 | ix,iy=x,y |
21 | # 当鼠标左键按下并移动是绘制图形。event 可以查看移动,flag 查看是否按下 |
22 | elif event==cv2.EVENT_MOUSEMOVE and flags==cv2.EVENT_FLAG_LBUTTON: |
23 | if drawing==True: |
24 | if mode==True: |
25 | cv2.rectangle(img,(ix,iy),(x,y),color,-1) |
26 | else: |
27 | # 绘制圆圈,小圆点连在一起就成了线,3 代表了笔画的粗细 |
28 | cv2.circle(img,(x,y),3,color,-1) |
29 | # 下面注释掉的代码是起始点为圆心,起点到终点为半径的 |
30 | # r=int(np.sqrt((x-ix)**2+(y-iy)**2)) |
31 | # cv2.circle(img,(x,y),r,(0,0,255),-1) |
32 | # 当鼠标松开停止绘画。 |
33 | elif event==cv2.EVENT_LBUTTONUP: |
34 | drawing==False |
35 | # if mode==True: |
36 | # cv2.rectangle(img,(ix,iy),(x,y),(0,255,0),-1) |
37 | # else: |
38 | # cv2.circle(img,(x,y),5,(0,0,255),-1) |
39 | img=np.zeros((512,512,3),np.uint8) |
40 | cv2.namedWindow('image') |
41 | cv2.createTrackbar('R','image',0,255,nothing) |
42 | cv2.createTrackbar('G','image',0,255,nothing) |
43 | cv2.createTrackbar('B','image',0,255,nothing) |
44 | cv2.setMouseCallback('image',draw_circle) |
45 | while(1): |
46 | cv2.imshow('image',img) |
47 | k=cv2.waitKey(1)&0xFF |
48 | if k==ord('m'): |
49 | mode=not mode |
50 | elif k==27: |
51 | break |
自己的实现
1 | import cv2 |
2 | import numpy as np |
3 | drawing = False |
4 | r,g,b=0,0,0 |
5 | def drawShape(event,x,y,flags,parms): |
6 | global drawing,sx,sy,ex,ey,r,g,b |
7 | if event == cv2.EVENT_LBUTTONDOWN: |
8 | sx,sy=x,y |
9 | drawing = True |
10 | elif event == cv2.EVENT_MOUSEMOVE and drawing == True: |
11 | cv2.circle(img,(x,y),3,(b,g,r),-1) |
12 | elif event == cv2.EVENT_LBUTTONUP: |
13 | drawing = False |
14 | def cCR(x): |
15 | global r,g,b |
16 | r=x |
17 | npclr[:] = [b,g,r] |
18 | def cCG(x): |
19 | global r,g,b |
20 | g=x |
21 | npclr[:] = [b, g, r] |
22 | def cCB(x): |
23 | global r,g,b |
24 | b=x |
25 | npclr[:] = [b, g, r] |
26 | img = np.zeros((512,512,3),np.uint8) |
27 | npclr = np.zeros((512,512,3),np.uint8) |
28 | |
29 | cv2.namedWindow("image") |
30 | cv2.namedWindow("nc") |
31 | cv2.createTrackbar("R","nc",0,255,cCR) |
32 | cv2.createTrackbar("G","nc",0,255,cCG) |
33 | cv2.createTrackbar("B","nc",0,255,cCB) |
34 | cv2.setMouseCallback("image",drawShape) |
35 | while(1): |
36 | cv2.imshow("image",img) |
37 | cv2.imshow("nc",npclr) |
38 | if(cv2.waitKey(1)&0xFF == 27): |
39 | break |
40 | cv2.destroyAllWindows() |
图像的基础操作
获取并修改像素值
可以根据像素的行和列的坐标获取他的像素值。对 $BGR$ 图像而言,返回值为 $B,G,R$ 的值。对灰度图像而言,会返回他的灰度值(亮度?intensity)
获取图像属性
图像的属性包括:行,列,通道,图像数据类型,像素数目等
img.shape 可以获取图像的形状。他的返回值是一个包含行数,列数,通道数的元组。
img.size可以返回图像的像素数目
img.dtype返回的是图像的数据类型(在OpenCV-Python代码中经常出现数据类型不一致,故在$debug$时要留意)
图像ROI
有时你需要对一幅图像的特定区域进行操作。例如我们要检测一副图像中 眼睛的位置,我们首先应该在图像中找到脸,再在脸的区域中找眼睛,而不是 直接在一幅图像中搜索。这样会提高程序的准确性和性能。
$ROI$也是使用 $Numpy$ 索引来获得的。现在我们选择球的部分并把他拷贝到图像的其他区域。
1 | import cv2 |
2 | import numpy as np |
3 | img=cv2.imread('roi.jpg') |
4 | ball=img[280:340,330:390] |
5 | img[273:333,100:160]=ball |
拆分及合并图像通道
有时我们需要对 $BGR$ 三个通道分别进行操作。这是你就需要把 $BGR$ 拆 分成单个通道。有时你需要把独立通道的图片合并成一个 $BGR$ 图像。可以这样做:
1 | import cv2 |
2 | import numpy as np |
3 | img=cv2.imread('/home/duan/workspace/opencv/images/roi.jpg') |
4 | b,g,r=cv2.split(img) |
5 | img=cv2.merge(b,g,r) |
或者:
1 | import cv2 |
2 | import numpy as np |
3 | img=cv2.imread('/home/duan/workspace/opencv/images/roi.jpg') |
4 | #获取图像蓝色通道 |
5 | b=img[:,:,0] |
6 | #将图像所有像素红色通道值赋为0 |
7 | img[:,:,2]=0 |
警告: cv2.split() 是一个比较耗时的操作。只有真正需要时才用它,能用 $Numpy$ 索引就尽量用
为图像扩边(填充)
如果想在图像周围创建一个边,就像相框一样,你可以使用 cv2.copyMakeBorder() 函数。这经常在卷积运算或 0 填充时被用到。这个函数包括如下参数:
- $src$ 输入图像
- $top, bottom, left, right$ 对应边界的像素数目。
- $borderType$ 要添加那种类型的边界,类型如下
cv2.BORDER_CONSTANT添加有颜色的常数值边界,还需要 下一个参数($value$)。cv2.BORDER_REFLECT边界元素的镜像。比如: $fedcba|abcdefgh|hgfedcb$cv2.BORDER_REFLECT_101orcv2.BORDER_DEFAULT跟上面一样,但稍作改动。例如: $gfedcb|abcdefgh|gfedcba$cv2.BORDER_REPLICATE重复最后一个元素。例如: $aaaaaa| abcdefgh|hhhhhhh$cv2.BORDER_WRAP不知道怎么说了, 就像这样: $cdefgh| abcdefgh|abcdefg$
- $value$ 边界颜色,如果边界的类型是
cv2.BORDER_CONSTANT
演示程序
1 | import cv2 |
2 | import numpy as np |
3 | from matplotlib import pyplot as plt |
4 | BLUE=[255,0,0] |
5 | img1=cv2.imread('opencv_logo.png') |
6 | replicate = cv2.copyMakeBorder(img1,10,10,10,10,cv2.BORDER_REPLICATE) |
7 | reflect = cv2.copyMakeBorder(img1,10,10,10,10,cv2.BORDER_REFLECT) |
8 | reflect101 = cv2.copyMakeBorder(img1,10,10,10,10,cv2.BORDER_REFLECT_101) |
9 | wrap = cv2.copyMakeBorder(img1,10,10,10,10,cv2.BORDER_WRAP) |
10 | constant= cv2.copyMakeBorder(img1,10,10,10,10,cv2.BORDER_CONSTANT,value=BLUE) |
11 | plt.subplot(231),plt.imshow(img1,'gray'),plt.title('ORIGINAL') |
12 | plt.subplot(232),plt.imshow(replicate,'gray'),plt.title('REPLICATE') |
13 | plt.subplot(233),plt.imshow(reflect,'gray'),plt.title('REFLECT') |
14 | plt.subplot(234),plt.imshow(reflect101,'gray'),plt.title('REFLECT_101') |
15 | plt.subplot(235),plt.imshow(wrap,'gray'),plt.title('WRAP') |
16 | plt.subplot(236),plt.imshow(constant,'gray'),plt.title('CONSTANT') |
17 | plt.show() |
图像上的 算术运算
图像加法
可以使用函数 cv2.add() 将两幅图像进行加法运算,当然也可以直接使 用 $numpy$,$res=img1+img$。两幅图像的大小,类型必须一致,或者第二个 图像可以使一个简单的标量值。
注意: $OpenCV$中的加法与 $Numpy$ 的加法是有所不同的。$OpenCV$ 的加法 是一种饱和操作,而 $Numpy$ 的加法是一种模操作。
例如下面的两个例子:
1 | x = np.uint8([250]) |
2 | y = np.uint8([10]) |
3 | print cv2.add(x,y) # 250+10 = 260 => 255 |
4 | print x+y # 250+10 = 260 % 256 = 4 |
这种差别在你对两幅图像进行加法时会更加明显。OpenCV 的结果会更好 一点。所以我们尽量使用 OpenCV 中的函数。
图像混合
这其实也是加法,但是不同的是两幅图像的权重不同,这就会给人一种混 合或者透明的感觉。图像混合的计算公式如下:
通过修改 α 的值(0 → 1),可以实现非常酷的混合。
现在我们把两幅图混合在一起。第一幅图的权重是 0.7,第二幅图的权重 是 0.3。函数 cv2.addWeighted() 可以按下面的公式对图片进行混合操作。
这里$\gamma$取值为0
1 | import cv2 |
2 | import numpy |
3 | img = cv2.imread("material/1.png") |
4 | img2 = cv2.imread("material/3.png") |
5 | dst = cv2.addWeighted(img,0.7,img2,0.3,0) |
6 | cv2.imshow("dst",dst) |
7 | cv2.waitKey(0) |
8 | cv2.destroyAllWindows() |
按位运算
这里包括的按位操作有:$AND,OR,NOT,XOR$ 等。当我们提取图像的 一部分,选择非矩形 $ROI$ 时这些操作会很有用(下一章就会明白)。下面的例子就是教我们如何改变一幅图的特定区域。 如果想把 $OpenCV$ 的标志放到另一幅图像上。如果使用加法,颜色会改 变,如果使用混合,会得到透明效果,但是我不想要透明。如果他是矩形我可以像上一章那样使用 ROI。但是他不是矩形。但是我们可以通过下面的按位运算实现:
1 | import cv2 |
2 | import numpy as np |
3 | # 加载图像 |
4 | img1 = cv2.imread('roi.jpg') |
5 | img2 = cv2.imread('opencv_logo.png') |
6 | # I want to put logo on top-left corner, So I create a ROI |
7 | rows,cols,channels = img2.shape |
8 | roi = img1[0:rows, 0:cols ] |
9 | # Now create a mask of logo and create its inverse mask also |
10 | img2gray = cv2.cvtColor(img2,cv2.COLOR_BGR2GRAY) |
11 | ret, mask = cv2.threshold(img2gray, 175, 255, cv2.THRESH_BINARY) |
12 | mask_inv = cv2.bitwise_not(mask) |
13 | # Now black-out the area of logo in ROI |
14 | # 取 roi 中与 mask 中不为零的值对应的像素的值,其他值为 0 |
15 | # 注意这里必须有 mask=mask 或者 mask=mask_inv, 其中的 mask= 不能忽略 |
16 | img1_bg = cv2.bitwise_and(roi,roi,mask = mask) |
17 | # 取 roi 中与 mask_inv 中不为零的值对应的像素的值,其他值为 0。 |
18 | # Take only region of logo from logo image. |
19 | img2_fg = cv2.bitwise_and(img2,img2,mask = mask_inv) |
20 | # Put logo in ROI and modify the main image |
21 | dst = cv2.add(img1_bg,img2_fg) |
22 | img1[0:rows, 0:cols ] = dst |
23 | cv2.imshow('res',img1) |
24 | cv2.waitKey(0) |
25 | cv2.destroyAllWindows() |
实现两张图片平滑过渡
1 | import cv2 |
2 | import numpy as np |
3 | img1 = cv2.imread("material/18.png") |
4 | img2 = cv2.imread("material/20.png") |
5 | for i in np.arange(0,1,0.01): |
6 | cv2.imshow("image",cv2.addWeighted(img1,1-i,img2,i,0)) |
7 | cv2.waitKey(40) |
8 | cv2.waitKey(0) |
9 | cv2.destroyAllWindows() |
程序性能检测及优化
使用 OpenCV 检测程序效率
cv2.getTickCount 函数返回从参考点到这个函数被执行的时钟数。所 以当你在一个函数执行前后都调用它的话,你就会得到这个函数的执行时间 (时钟数)。
cv2.getTickFrequency 返回时钟频率,或者说每秒钟的时钟数。所以 你可以按照下面的方式得到一个函数运行了多少秒:
1 | import cv2 |
2 | import numpy as np |
3 | e1 = cv2.getTickCount() |
4 | # your code execution |
5 | e2 = cv2.getTickCount() |
6 | time = (e2 - e1)/ cv2.getTickFrequency() |
注 意: 你 也 可 以 中 time 模 块 实 现 上 面 的 功 能。 但 是 要 用 的 函 数 是 time.time() 而不是 cv2.getTickCount()。比较一下这两个结果的差别吧。
OpenCV的默认优化
OpenCV 中的很多函数都被优化过(使用 $SSE2$,$AVX$ 等)。也包含一些没有被优化的代码。如果我们的系统支持优化的话要尽量利用这一点。在编译时优化是被默认开启的。因此 OpenCV 运行的就是优化后的代码,如果你把优化关闭的话就只能执行低效的代码了。可以使用函数 cv2.useOptimized() 来查看优化是否被开启了,使用函数 cv2.setUseOptimized() 来开启优化。
1 | import cv2 |
2 | import numpy as np |
3 | # check if optimization is enabled |
4 | In [5]: cv2.useOptimized() |
5 | Out[5]: True |
6 | In [6]: %timeit res = cv2.medianBlur(img,49) |
7 | 10 loops, best of 3: 34.9 ms per loop |
8 | # Disable it |
9 | In [7]: cv2.setUseOptimized(False) |
10 | In [8]: cv2.useOptimized() |
11 | Out[8]: False |
12 | In [9]: %timeit res = cv2.medianBlur(img,49) |
13 | 10 loops, best of 3: 64.1 ms per loop |
优化后中值滤波的速度是原来的两倍。如果查看源代码的话会发现中值滤波是被 SIMD 优化的。所以可以在代码的开始处开启优化 (记住优化是默认开启的)。
在 $IPython$ 中检测程序效率
有时你需要比较两个相似操作的效率,这时你可以使用 $IPython$ 为你提供的魔法命令%time。他会让代码运行好几次从而得到一个准确的(运行)时间。它也可以被用来测试单行代码的效率。
1 | In [1]: import cv2 |
2 | In [2]: import numpy as np |
3 | In [3]: x = 5 |
4 | In [4]: %timeit y=x**2 |
5 | 270 ns ± 16.2 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each) |
6 | In [5]: %timeit y=x*x |
7 | 41.5 ns ± 3.73 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each) |
8 | In [6]: z = np.uint8([5]) |
9 | In [7]: %timeit y=z*z |
10 | 422 ns ± 7.82 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each) |
11 | In [8]: %timeit y=np.square(z) |
12 | 430 ns ± 26.7 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each) |
注意: $Python$ 的标量计算比 $Numpy$ 的标量计算要快。对于仅包含一两个 元素的操作 $Python$ 标量比 $Numpy$ 的数组要快。但是当数组稍微大一点时 $Numpy$ 就会胜出了。
下面比较一下 cv2.countNonZero() 和 np.count_nonzero()。
1 | import cv2 |
2 | import numpy as np |
3 | In [35]: %timeit z = cv2.countNonZero(img) |
4 | 100000 loops, best of 3: 15.8 us per loop |
5 | In [36]: %timeit z = np.count_nonzero(img) |
6 | 1000 loops, best of 3: 370 us per loop |
注意:一般情况下 $OpenCV$ 的函数要比 $Numpy$ 函数快。所以对于相同的操作最好使用 $OpenCV$ 的函数。当然也有例外,尤其是当使用 $Numpy$ 对视图 (而非复制)进行操作时。
更多 $IPython$ 的魔法命令
还有几个魔法命令可以用来检测程序的效率,$profiling$,$line profiling$, 内存使用等。他们都有完善的文档,感兴趣的可以自己学习一下。
效率优化技术
有些技术和编程方法可以让我们最大的发挥 $Python$ 和 $Numpy$ 的威力。 我们这里仅仅提一下相关的,你可以通过超链接查找更多详细信息。最重要的一点是:首先用简单的方式实现你的算法(结果正确最重要),当结果正确后,再使用上面的提到的方法找到程序的瓶颈来优化它。
- 尽量避免使用循环,尤其双层三层循环,它们天生就是非常慢的。
- 算法中尽量使用向量操作,因为 $Numpy$ 和 $OpenCV$ 都对向量操作进行 了优化。
- 利用高速缓存一致性。
- 没有必要的话就不要复制数组。使用视图来代替复制。数组复制是非常浪费资源的。
就算进行了上述优化,如果你的程序还是很慢,或者说大的训话不可避免的话, 应该尝试使用其他的包,比如说 $Cython$,来加速程序。
OpenCV 中的数学工具
缺失
OpenCV 中的图像处理
颜色空间转换
转换颜色空间
在 OpenCV 中有超过 150 中进行颜色空间转换的方法。但是你以后就会 发现我们经常用到的也就两种:$BGR↔Gray$ 和 $BGR↔HSV$。
我们要用到的函数是:cv2.cvtColor(input_image,flag),其中 $flag$ 就是转换类型。
对于 $BGR↔Gray$ 的转换,我们要使用的 $flag$ 就是 cv2.COLOR_BGR2GRAY。同样对于 $BGR↔HSV$ 的转换,我们用的 $flag$ 就是 cv2.COLOR_BGR2HSV。 可以通过下面的命令得到所有可用的 $flag$。
1 | import cv2 |
2 | flags=[i for in dir(cv2) if i startswith('COLOR_')] |
3 | print flags |
注意: 在 $OpenCV$ 的 $HSV$ 格式中,$H$(色彩/色度)的取值范围是 $[0,179]$, $S$(饱和度)的取值范围 $[0,255]$,$V$(亮度)的取值范围 $[0,255]$。但是不同的软件使用的值可能不同。所以当你需要拿 $OpenCV$ 的 $HSV$ 值与其他软件的 $HSV$ 值进行对比时,一定要记得归一化。
物体跟踪
知道怎样将一幅图像从 $BGR$ 转换到 $HSV$ 了,我们可以利用这一点来提取带有某个特定颜色的物体。在 $HSV$ 颜色空间中要比在 $BGR$ 空间 中更容易表示一个特定颜色。在我们的程序中,我们要提取的是一个蓝色的物体。下面就是就是我们要做的几步:
- 从视频中获取每一帧图像
- 将图像转换到 HSV 空间
- 设置 HSV 阈值到蓝色范围。
- 获取蓝色物体,当然我们还可以做其他任何我们想做的事,比如:在蓝色物体周围画一个圈。
1 | import cv2 |
2 | import numpy as np |
3 | cap=cv2.VideoCapture(0) |
4 | while(1): |
5 | # 获取每一帧 |
6 | ret,frame=cap.read() |
7 | # 转换到 HSV |
8 | hsv=cv2.cvtColor(frame,cv2.COLOR_BGR2HSV) |
9 | # 设定蓝色的阈值 |
10 | lower_blue=np.array([110,50,50]) |
11 | upper_blue=np.array([130,255,255]) |
12 | # 根据阈值构建掩模 |
13 | mask=cv2.inRange(hsv,lower_blue,upper_blue) |
14 | # 对原图像和掩模进行位运算 |
15 | res=cv2.bitwise_and(frame,frame,mask=mask) |
16 | # 显示图像 |
17 | cv2.imshow('frame',frame) |
18 | cv2.imshow('mask',mask) |
19 | cv2.imshow('res',res) |
20 | k=cv2.waitKey(5)&0xFF |
21 | if k==27: |
22 | break |
23 | # 关闭窗口 |
24 | cv2.destroyAllWindows() |
注意: 这是物体跟踪中最简单的方法。当你学习了轮廓之后,你就会学到更多相关知识,那是你就可以找到物体的重心,并根据重心来跟踪物体,仅仅在摄像头前挥挥手就可以画出同的图形,或者其他更有趣的事。
找到要跟踪对象的 $HSV$ 值
函数 cv2.cvtColor() 也可以用到这里。但是现在你要传入的参数是(你想要的)$BGR$ 值而不是一副图。例如,我们要找到绿色的 $HSV$ 值,我们只需在终端输入以下命令:
1 | import cv2 |
2 | import numpy as np |
3 | green=np.uint8([0,255,0]) |
4 | hsv_green=cv2.cvtColor(green,cv2.COLOR_BGR2HSV) |
5 | print hsv_green |
6 | # [[[60 255 255]]] |
现在你可以分别用 [H-100,100,100] 和 [H+100,255,255] 做上下阈值。除了这个方法之外,你可以使用任何其他图像编辑软件(例如 GIMP) 或者在线转换软件找到相应的 $HSV$ 值,但是最后别忘了调节 $HSV$ 的范围。
几何变换
OpenCV 提供了两个变换函数,cv2.warpAffine 和 cv2.warpPerspective, 使用这两个函数你可以实现所有类型的变换。cv2.warpAffine 接收的参数是 $2 × 3$ 的变换矩阵,而 cv2.warpPerspective 接收的参数是 $3 × 3$ 的变换矩阵。
扩展缩放
扩展缩放只是改变图像的尺寸大小。OpenCV 提供的函数 cv2.resize() 可以实现这个功能。图像的尺寸可以自己手动设置,你也可以指定缩放因子。我们可以选择使用不同的插值方法。在缩放时我们推荐使用 cv2.INTER_AREA, 在扩展时我们推荐使用 cv2.INTER_CUBIC(慢) 和 v2.INTER_LINEAR。 默认情况下所有改变图像尺寸大小的操作使用的插值方法都是 cv2.INTER_LINEAR。 你可以使用下面任意一种方法改变图像的尺寸:
1 | import cv2 |
2 | import numpy as np |
3 | img=cv2.imread('messi5.jpg') |
4 | #Resize(src, dst, interpolation=CV_INTER_LINEAR) |
5 | # 下面的 None 本应该是输出图像的尺寸,但是因为后边我们设置了缩放因子 |
6 | # 因此这里为 None |
7 | res=cv2.resize(img,None,fx=2,fy=2,interpolation=cv2.INTER_CUBIC) |
8 | #OR |
9 | # 这里呢,我们直接设置输出图像的尺寸,所以不用设置缩放因子 |
10 | height,width=img.shape[:2] |
11 | res=cv2.resize(img,(2*width,2*height),interpolation=cv2.INTER_CUBIC) |
12 | while(1): |
13 | cv2.imshow('res',res) |
14 | cv2.imshow('img',img) |
15 | if cv2.waitKey(1) & 0xFF == 27: |
16 | break |
17 | cv2.destroyAllWindows() |
平移
平移就是将对象换一个位置。如果你要沿$(x,y)$方向移动,移动的距离 是$(tx,ty)$,你可以以下面的方式构建移动矩阵:
你可以使用 $Numpy$ 构建这个矩阵(数据类型是 $np.float32$),然后把它传给函数 cv2.warpAffine()。
1 | cv2.warpAffine(src, M, dsize[, dst[, flags[, borderMode[, borderValue]]]]) → dst |
其中:
$src$ – 输入图像。
$M$ – 变换矩阵。
$dsize$ – 输出图像的大小。
$flags$ – 插值方法的组合(int 类型!)
$borderMode$ – 边界像素模式(int 类型!)
$borderValue$ – (重点!)边界填充值; 默认情况下,它为0。
上述参数中:
$M$作为仿射变换矩阵,一般反映平移或旋转的关系,为$InputArray$类型的$2×3$的变换矩阵。
$flags$表示插值方式,默认为 flags=cv2.INTER_LINEAR,表示线性插值,
此外还有:
cv2.INTER_NEAREST(最近邻插值)
cv2.INTER_AREA (区域插值)
cv2.INTER_CUBIC(三次样条插值)
cv2.INTER_LANCZOS4($Lanczos$插值)
日常进行仿射变换时,在只设置前三个参数的情况下,如 cv2.warpAffine(img,M,(rows,cols))可以实现基本的仿射变换效果,但因为边界填充值为$(0,0,0)$ ,可能会出现“黑边”现象。要使周围填充白色,可以:
1 | cv2.warpAffine(img,M,(lengh,lengh),borderValue=(255,255,255)) |
警告: 函数 cv2.warpAffine() 的第三个参数的是输出图像的大小,它的格式应该是图像的(宽,高)。应该记住的是图像的宽对应的是列数,高对应的是行数。
下面的代码将图像按$(100,50)$ 平移
1 | import cv2 |
2 | import numpy as np |
3 | cv2.namedWindow("image") |
4 | img = cv2.imread("material/0.png") |
5 | M = np.float32([[1,0,100],[0,1,50]]) |
6 | res = cv2.warpAffine(img,M,img.shape[:2]) |
7 | cv2.imshow("image",res) |
8 | cv2.waitKey(0) |
9 | cv2.destroyAllWindows() |
旋转
对一个图像旋转角度 $θ$, 需要使用到下面形式的旋转矩阵。
但是 OpenCV 允许绕任意地方进行旋转,但是旋转矩阵的形式应该修改为
其中:
为了构建这个旋转矩阵,$OpenCV$ 提供了一个函数:cv2.getRotationMatrix2D。 下面的例子是在不缩放的情况下将图像旋转 $90$ 度。
1 | import cv2 |
2 | import numpy as np |
3 | cv2.namedWindow("image") |
4 | img = cv2.imread("material/0.png") |
5 | width,height = img.shape[:2] |
6 | # 这里的第一个参数为旋转中心,第二个为旋转角度,第三个为旋转后的缩放因子 |
7 | # 可以通过设置旋转中心,缩放因子,以及窗口大小来防止旋转后超出边界的问题 |
8 | M = cv2.getRotationMatrix2D((width//2,height//2),45,0.6) |
9 | # 第三个参数是输出图像的尺寸中心 |
10 | res = cv2.warpAffine(img,M,(600,600)) |
11 | |
12 | # 旋转之后图像外的部分消失 |
13 | # M2 = np.float32([[1,0,100],[0,1,50]]) |
14 | # res = cv2.warpAffine(res,M2,(600,600)) |
15 | |
16 | cv2.imshow("image",res) |
17 | cv2.imwrite("ratation.png",res) |
18 | cv2.waitKey(0) |
19 | cv2.destroyAllWindows() |

仿射变换
在仿射变换中,原图中所有的平行线在结果图像中同样平行。为了创建这 个矩阵我们需要从原图像中找到三个点以及他们在输出图像中的位置。然后 cv2.getAffineTransform 会创建一个 $2*3$ 的矩阵,最后这个矩阵会被传给函数 cv2.warpAffine。
1 | import cv2 |
2 | import numpy as np |
3 | from matplotlib import pyplot as plt |
4 | img=cv2.imread('material/0.png') |
5 | rows,cols,ch=img.shape |
6 | pts1=np.float32([[50,50],[200,50],[50,200]]) |
7 | pts2=np.float32([[10,100],[200,50],[100,250]]) |
8 | M=cv2.getAffineTransform(pts1,pts2) |
9 | res=cv2.warpAffine(img,M,(cols,rows)) |
10 | cv2.imshow("image",res) |
11 | cv2.imwrite("affine.png",res) |
12 | cv2.waitKey(0) |
13 | cv2.destroyAllWindows() |

透视变换
对于视角变换,我们需要一个 $3*3$ 变换矩阵。在变换前后直线还是直线。 要构建这个变换矩阵,你需要在输入图像上找 $4$ 个点,以及他们在输出图像上对应的位置。这四个点中的任意三个都不能共线。这个变换矩阵可以有函数 cv2.getPerspectiveTransform() 构建。然后把这个矩阵传给函数 cv2.warpPerspective。
1 | import cv2 |
2 | import numpy as np |
3 | from matplotlib import pyplot as plt |
4 | img=cv2.imread('material/0.png') |
5 | img = cv2.resize(img,(300,300),cv2.INTER_AREA) |
6 | rows,cols,ch=img.shape |
7 | print(img.shape) |
8 | pts1 = np.float32([[56,65],[368,52],[28,387],[389,390]]) |
9 | pts2 = np.float32([[0,0],[300,0],[0,300],[300,300]]) |
10 | M=cv2.getPerspectiveTransform(pts1,pts2) |
11 | dst=cv2.warpPerspective(img,M,(300,300)) |
12 | cv2.imshow("image",dst) |
13 | cv2.waitKey(0) |
14 | plt.show() |
图像阈值
简单阈值
与名字一样,这种方法非常简单。但像素值高于阈值时,我们给这个像素赋予一个新值(可能是白色),否则我们给它赋予另外一种颜色(也许是黑色)。 这个函数就是 cv2.threshhold()。
1 | cv2.threshold (src, thresh, maxval, type) |
| 参数 | 解释 |
|---|---|
| src | 源图片,必须是单通道 |
| thresh | 阈值,取值范围0~255 |
| maxval | 填充色,取值范围0~255 |
| type | 阈值类型,见下表 |
这个函数的第一个参数就是原图像,原图像应该是灰度图。第二个参数就是用来对像素值进行分类的阈值。第三个参数就是当像素值高于(有时是小于)阈值时应该被赋予的新的像素值。OpenCV 提供了多种不同的阈值方法,这是由第四个参数来决定的。这些方法包括:
| type | 解释 |
|---|---|
| $cv2.THRESH_BINARY$ | 二进制阈值化,非黑即白 |
| $cv2.THRESH_BINARY_INV$ | 反二进制阈值化,非白即黑 |
| $cv2.THRESH_TRUNC$ | 截断阈值化 ,大于阈值设为阈值 |
| $cv2.THRESH_TOZERO$ | 阈值化为0 ,小于阈值设为0 |
| $cv2.THRESH_TOZERO_INV$ | 反阈值化为0 ,大于阈值设为0 |
这个函数有两个返回值,第一个为 $retVal$,我们后面会解释。第二个就是 阈值化之后的结果图像了。
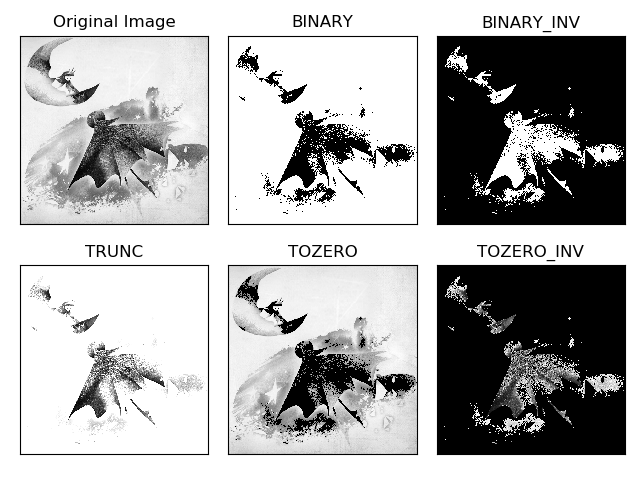
1 | import cv2 |
2 | import numpy as np |
3 | from matplotlib import pyplot as plt |
4 | img=cv2.imread('material/11.png',0) |
5 | ret,thresh1=cv2.threshold(img,127,255,cv2.THRESH_BINARY) |
6 | ret,thresh2=cv2.threshold(img,127,255,cv2.THRESH_BINARY_INV) |
7 | ret,thresh3=cv2.threshold(img,127,255,cv2.THRESH_TRUNC) |
8 | ret,thresh4=cv2.threshold(img,127,255,cv2.THRESH_TOZERO) |
9 | ret,thresh5=cv2.threshold(img,127,255,cv2.THRESH_TOZERO_INV) |
10 | titles = ['Original Image','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV'] |
11 | images = [img, thresh1, thresh2, thresh3, thresh4, thresh5] |
12 | for i in range(6): |
13 | plt.subplot(2,3,i+1),plt.imshow(images[i],'gray') |
14 | plt.title(titles[i]) |
15 | plt.xticks([]),plt.yticks([]) |
16 | plt.show() |
自适应阈值
在前面的部分我们使用是全局阈值,整幅图像采用同一个数作为阈值。但是这种方法并不适应于所有情况,尤其是当同一幅图像上的不同部分的具有不同亮度时。这种情况下我们需要采用自适应阈值cv2.adaptiveThreshold()。此时的阈值是根据图像上的每一个小区域计算与其对应的阈值。因此在同一幅图像上的不同区域采用的是不同的阈值,从而使我们能在亮度不同的情况下得到更好的结果。
这种方法需要我们指定三个参数,返回值只有一个。
$Adaptive Method$- 指定计算阈值的方法。
cv2.ADPTIVE_THRESH_MEAN_C:阈值取自相邻区域的平均值cv2.ADPTIVE_THRESH_GAUSSIAN_C:阈值取值相邻区域的加权和,权重为一个高斯窗口。
$Block Size$ - 邻域大小(用来计算阈值的区域大小)。
$C$ - 这就是是一个常数,阈值就等于平均值或者加权平均值减去这个常数。
我们使用下面的代码来展示简单阈值与自适应阈值的差别:
1 | import numpy as np |
2 | import cv2 |
3 | import matplotlib.pyplot as plt |
4 | img = cv2.imread("material/1.jpg",0) |
5 | # 中值滤波 |
6 | img = cv2.medianBlur(img,5) |
7 | ret, th1 = cv2.threshold(img,127,255,cv2.THRESH_BINARY) |
8 | #11 为 Block size, 2 为 C 值 |
9 | th2 = cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_THRESH_MEAN_C,cv2.THRESH_BINARY,11,2) |
10 | th3 = cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,cv2.THRESH_BINARY,11,2) |
11 | th2 = cv2.medianBlur(th2,7) |
12 | th3 = cv2.medianBlur(th3,7) |
13 | titles = ['Original Image', 'Global Thresholding (v = 127)','Adaptive Mean Thresholding', 'Adaptive Gaussian Thresholding'] |
14 | images = [img, th1,th2,th3] |
15 | for i in range(4): |
16 | plt.subplot(2,2,i+1),plt.imshow(images[i],'gray') |
17 | plt.title(titles[i]) |
18 | plt.xticks([]),plt.yticks([]) |
19 | plt.show() |

$Otsu’s$ 二值化
在第一部分中我们提到过 $retVal$,当我们使用 $Otsu$ 二值化时会用到它。
在使用全局阈值时,我们就是随便给了一个数来做阈值,那我们怎么知道这个数的好坏呢?答案就是不停的尝试。如果是一副双峰图像(简单来说双峰图像是指图像直方图中存在两个峰)呢?我们岂不是应该在两个峰之间的峰谷选一个值作为阈值?这就是 $Otsu$ 二值化要做的。简单来说就是对一副双峰图像自动根据其直方图计算出一个阈值。(对于非双峰图像,这种方法得到的结果可能会不理想)。 这里用到的函数还是 cv2.threshold(),但是需要多传入一个参数 (flag):cv2.THRESH_OTSU。这时要把阈值设为 0。然后算法会找到最优阈值,这个最优阈值就是返回值 $retVal$。如果不使用 $Otsu$ 二值化,返回的 $retVal$ 值与设定的阈值相等。
例程:
1 | import cv2 |
2 | import numpy as np |
3 | from matplotlib import pyplot as plt |
4 | img = cv2.imread('noisy2.png',0) |
5 | # global thresholding |
6 | ret1,th1 = cv2.threshold(img,127,255,cv2.THRESH_BINARY) |
7 | # Otsu's thresholding |
8 | ret2,th2 = cv2.threshold(img,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU) |
9 | # Otsu's thresholding after Gaussian filtering |
10 | #(5,5)为高斯核的大小,0 为标准差 |
11 | blur = cv2.GaussianBlur(img,(5,5),0) |
12 | # 阈值一定要设为 0! |
13 | ret3,th3 = cv2.threshold(blur,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU) |
14 | # plot all the images and their histograms |
15 | images = [img, 0, th1, |
16 | img, 0, th2, |
17 | blur, 0, th3] |
18 | titles = ['Original Noisy Image','Histogram','Global Thresholding (v=127)', |
19 | 'Original Noisy Image','Histogram',"Otsu's Thresholding", |
20 | 'Gaussian filtered Image','Histogram',"Otsu's Thresholding"] |
21 | # 这里使用了 pyplot 中画直方图的方法,plt.hist, 要注意的是它的参数是一维数组 |
22 | # 所以这里使用了(numpy)ravel 方法,将多维数组转换成一维,也可以使用 flatten 方法 |
23 | #ndarray.flat 1-D iterator over an array. |
24 | #ndarray.flatten 1-D array copy of the elements of an array in row-major order. |
25 | for i in range(3): |
26 | plt.subplot(3,3,i*3+1),plt.imshow(images[i*3],'gray') |
27 | plt.title(titles[i*3]), plt.xticks([]), plt.yticks([]) |
28 | plt.subplot(3,3,i*3+2),plt.hist(images[i*3].ravel(),256) |
29 | plt.title(titles[i*3+1]), plt.xticks([]), plt.yticks([]) |
30 | plt.subplot(3,3,i*3+3),plt.imshow(images[i*3+2],'gray') |
31 | plt.title(titles[i*3+2]), plt.xticks([]), plt.yticks([]) |
32 | plt.show() |
$otsu$工作原理
对于图像 I(x,y),前景(即目标)和背景的分割阈值记作 T,属于前景的像素点数占整幅图像的比例记为 ω0,平均灰度为 μ0;背景像素点数占整幅图像的比例为 ω1,平均灰度为 μ1;整幅图像的平均灰度记为μ,类间方差记为g。
假设图像大小为$M×N$,图像中像素的灰度值小于阈值$T$的像素个数为 $N_0$,像素灰度大于阈值$T$的像素个数为 $N_1$,那么:
采用遍历的方法使得类间方差$g$最大的阈值$T$,即为所求。$Ostu$方法可以形象地理解为:求取直方图有两个峰值的图像中那两个峰值之间的低谷值$T$。
1 | import cv2 |
2 | import numpy as np |
3 | img = cv2.imread('noisy2.png',0) |
4 | blur = cv2.GaussianBlur(img,(5,5),0) |
5 | # find normalized_histogram, and its cumulative distribution function |
6 | # 计算归一化直方图 |
7 | #CalcHist(image, accumulate=0, mask=NULL) |
8 | hist = cv2.calcHist([blur],[0],None,[256],[0,256]) |
9 | hist_norm = hist.ravel()/hist.max() |
10 | Q = hist_norm.cumsum() |
11 | |
12 | bins = np.arange(256) |
13 | |
14 | fn_min = np.inf |
15 | thresh = -1 |
16 | |
17 | for i in range(1,256): |
18 | p1,p2 = np.hsplit(hist_norm,[i]) # probabilities |
19 | q1,q2 = Q[i],Q[255]-Q[i] # cum sum of classes |
20 | b1,b2 = np.hsplit(bins,[i]) # weights |
21 | # finding means and variances |
22 | m1,m2 = np.sum(p1*b1)/q1, np.sum(p2*b2)/q2 |
23 | v1,v2 = np.sum(((b1-m1)**2)*p1)/q1,np.sum(((b2-m2)**2)*p2)/q2 |
24 | # calculates the minimization function |
25 | fn = v1*q1 + v2*q2 |
26 | if fn < fn_min: |
27 | fn_min = fn |
28 | thresh = i |
29 | # find otsu's threshold value with OpenCV function |
30 | ret, otsu = cv2.threshold(blur,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU) |
31 | print thresh,ret |
个人实现:
1 | import numpy as np |
2 | import cv2 |
3 | import matplotlib.pyplot as plt |
4 | def otsu(img): |
5 | sum_pix = img.size |
6 | th = 0 |
7 | mxdelta = 0 |
8 | for t in range(0,256): |
9 | mask = img<=t |
10 | w0 = np.sum(mask)/sum_pix |
11 | w1 = 1 - w0 |
12 | if np.sum(mask!=0)!=0: |
13 | k = img[mask] |
14 | u0 = np.mean(k) |
15 | else :u0 = 0 |
16 | if np.sum(mask!=0)!=sum_pix: |
17 | k = img[(~mask)] |
18 | u1 = np.mean(k) |
19 | else :u1 = 0 |
20 | delta = w0 * w1 * (u0-u1) ** 2 |
21 | if delta > mxdelta : |
22 | mxdelta = delta |
23 | th = t |
24 | return th |
25 | img = cv2.imread("material/9.png",0) |
26 | img = cv2.medianBlur(img,3) |
27 | th = otsu(img) |
28 | ret,dst = cv2.threshold(img,th,255,cv2.THRESH_BINARY) |
29 | ret2,dst2 = cv2.threshold(img,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU) |
30 | print(ret,ret2) |
31 | cv2.namedWindow("image",cv2.WINDOW_NORMAL) |
32 | cv2.namedWindow("image2",cv2.WINDOW_NORMAL) |
33 | cv2.imshow("image",dst) |
34 | cv2.imshow("image2",dst2) |
35 | plt.hist(img.ravel(),256) |
36 | plt.show() |
37 | cv2.waitKey(0) |
38 | cv2.destroyAllWindows() |
图像平滑
$2D$卷积
与信号一样,我们也可以对 $2D$ 图像实施低通滤波$(LPF)$,高通滤波 $(HPF)$等。$LPF$ 帮助我们去除噪音,模糊图像。$HPF$ 帮助我们找到图像的边缘。
$OpenCV$ 提供的函数 cv.filter2D() 可以让我们对一幅图像进行卷积操作。下面将对一幅图像使用平均滤波器。下面是一个 $5*5$ 的平均滤波器核:
操作如下:将核放在图像的一个像素 $A$ 上,求与核对应的图像上 $25(5*5)$ 个像素的和,在取平均数,用这个平均数替代像素 $A$ 的值。重复以上操作直到将图像的每一个像素值都更新一边。代码如下:
1 | import cv2 |
2 | import numpy as np |
3 | from matplotlib import pyplot as plt |
4 | img = cv2.imread('opencv_logo.png') |
5 | kernel = np.ones((5,5),np.float32)/25 |
6 | #cv.Filter2D(src, dst, kernel, anchor=(-1, -1)) |
7 | #ddepth –desired depth of the destination image; |
8 | #if it is negative, it will be the same as src.depth(); |
9 | #the following combinations of src.depth() and ddepth are supported: |
10 | #src.depth() = CV_8U, ddepth = -1/CV_16S/CV_32F/CV_64F |
11 | #src.depth() = CV_16U/CV_16S, ddepth = -1/CV_32F/CV_64F |
12 | #src.depth() = CV_32F, ddepth = -1/CV_32F/CV_64F |
13 | #src.depth() = CV_64F, ddepth = -1/CV_64F |
14 | #when ddepth=-1, the output image will have the same depth as the source. |
15 | dst = cv2.filter2D(img,-1,kernel) |
16 | plt.subplot(121),plt.imshow(img),plt.title('Original') |
17 | plt.xticks([]), plt.yticks([]) |
18 | plt.subplot(122),plt.imshow(dst),plt.title('Averaging') |
19 | plt.xticks([]), plt.yticks([]) |
20 | plt.show() |
图像模糊(图像平滑)
使用低通滤波器可以达到图像模糊的目的。这对与去除噪音很有帮助。其实就是去除图像中的高频成分(比如:噪音,边界)。所以边界也会被模糊一 点。(当然,也有一些模糊技术不会模糊掉边界)。$OpenCV $提供了四种模糊技术。
平均
这是由一个归一化卷积框完成的。他只是用卷积框覆盖区域所有像素的平均值来代替中心元素。可以使用函数 cv2.blur() 和 cv2.boxFilter() 来完成这个任务。可以同看查看文档了解更多卷积框的细节。我们需要设定卷积框的宽和高。下面是一个 $3 * 3$ 的归一化卷积框:
注意:如果你不想使用归一化卷积框,你应该使用 cv2.boxFilter(),这时要 传入参数 normalize=False。(cv2.blur等价于· normalize = ture 的 cv2.boxFilter)
这是与上一个代码效果相同的例子:
1 | import cv2 |
2 | import numpy as np |
3 | from matplotlib import pyplot as plt |
4 | img = cv2.imread('opencv_logo.png') |
5 | blur = cv2.blur(img,(5,5)) |
6 | plt.subplot(121),plt.imshow(img),plt.title('Original') |
7 | plt.xticks([]), plt.yticks([]) |
8 | plt.subplot(122),plt.imshow(blur),plt.title('Blurred') |
9 | plt.xticks([]), plt.yticks([]) |
10 | plt.show() |
高斯模糊
现在把卷积核换成高斯核(简单来说,方框不变,将原来每个方框的值是相等的,现在里面的值是符合高斯分布的,方框中心的值最大,其余方框根据距离中心元素的距离递减,构成一个高斯小山包。原来的求平均数现在变成求加权平均数,全就是方框里的值)。实现的函数是 cv2.GaussianBlur()。我们需要指定高斯核的宽和高(必须是奇数)。以及高斯函数沿 $X,Y$ 方向的标准差。如果我们只指定了 $X$ 方向的的标准差,$Y$ 方向也会取相同值。如果两个标准差都是 0,那么函数会根据核函数的大小自己计算。高斯滤波可以有效的从图像中去除高斯噪音。 如果你愿意的话,你也可以使用函数 cv2.getGaussianKernel() 自己构建一个高斯核。 如果要使用高斯模糊的话,上边的代码应该写成:
1 | #0 是指根据窗口大小(5,5)来计算高斯函数标准差 |
2 | blur = cv2.GaussianBlur(img,(5,5),0) |
中值模糊
顾名思义就是用与卷积框对应像素的中值来替代中心像素的值。这个滤波器经常用来去除椒盐噪声。前面的滤波器都是用计算得到的一个新值来取代中心像素的值,而中值滤波是用中心像素周围(也可以使他本身)的值来取代他。 他能有效的去除噪声。卷积核的大小也应该是一个奇数。
在这个例子中,我们给原始图像加上 $50\%$ 的噪声然后再使用中值模糊。
1 | median = cv2.medianBlur(img,5) |
双边滤波
函数 cv2.bilateralFilter() 能在保持边界清晰的情况下有效的去除噪音。但是这种操作与其他滤波器相比会比较慢。我们已经知道高斯滤波器是求中心点邻近区域像素的高斯加权平均值。这种高斯滤波器只考虑像素之间的空间关系,而不会考虑像素值之间的关系(像素的相似度)。所以这种方法不会考虑一个像素是否位于边界。因此边界也会别模糊掉,而这正不是我们想要。
双边滤波在同时使用空间高斯权重和灰度值相似性高斯权重。空间高斯函数确保只有邻近区域的像素对中心点有影响,灰度值相似性高斯函数确保只有与中心像素灰度值相近的才会被用来做模糊运算。所以这种方法会确保边界不会被模糊掉,因为边界处的灰度值变化比较大。
进行双边滤波的代码如下:
1 | #cv2.bilateralFilter(src, d, sigmaColor, sigmaSpace) |
2 | #d – Diameter of each pixel neighborhood that is used during filtering. |
3 | # If it is non-positive, it is computed from sigmaSpace |
4 | #9 邻域直径,两个 75 分别是空间高斯函数标准差,灰度值相似性高斯函数标准差 |
5 | blur = cv2.bilateralFilter(img,9,75,75) |
比较
1 | import cv2 |
2 | import numpy as np |
3 | img = cv2.imread("material/6.png") |
4 | res = img |
5 | font = cv2.FONT_HERSHEY_SIMPLEX |
6 | tmp1 = cv2.blur(img,(5,5)) |
7 | cv2.putText(tmp1,"blur",(10,50),font,1,0,2) |
8 | tmp2 = cv2.GaussianBlur(img,(5,5),0) |
9 | cv2.putText(tmp2,"Gaussian",(10,50),font,1,0,2) |
10 | tmp3 = cv2.medianBlur(img,5) |
11 | cv2.putText(tmp3,"median",(10,50),font,1,0,2) |
12 | tmp4 = cv2.bilateralFilter(img,5,75,75) |
13 | cv2.putText(tmp4,"bilateral",(10,50),font,1,0,2) |
14 | res = np.vstack((np.hstack((tmp1,tmp2)),np.hstack((tmp3,tmp4)))) |
15 | cv2.namedWindow("image",cv2.WINDOW_NORMAL) |
16 | cv2.imshow("image",res) |
17 | cv2.imwrite("blur.png",res) |
18 | cv2.waitKey(0) |
19 | cv2.destroyAllWindows() |

形态学转换
形态学操作是根据图像形状进行的简单操作。一般情况下对二值化图像进行的操作。需要输入两个参数,一个是原始图像,第二个被称为结构化元素或核,它是用来决定操作的性质的。两个基本的形态学操作是腐蚀和膨胀。他们的变体构成了开运算,闭运算,梯度等。
腐蚀
就像土壤侵蚀一样,这个操作会把前景物体的边界腐蚀掉(但是前景仍然是白色)。这是怎么做到的呢?卷积核沿着图像滑动,如果与卷积核对应的原图像的所有像素值都是 $1$,那么中心元素就保持原来的像素值,否则就变为零。 这回产生什么影响呢?根据卷积核的大小靠近前景的所有像素都会被腐蚀掉(变为 $0$),所以前景物体会变小,整幅图像的白色区域会减少。这对于去除白噪声很有用,也可以用来断开两个连在一块的物体等。 这里我们有一个例子,使用一个 $5*5$ 的卷积核,其中所有的值都是 $1$ 。让我们看看他是如何工作的:
1 | import cv2 |
2 | import numpy as np |
3 | img = cv2.imread('j.png',0) |
4 | kernel = np.ones((5,5),np.uint8) |
5 | #dst=cv2.erode(src, kernel[, dst[, anchor[, iterations[, borderType[, borderValue]]]]]) |
6 | erosion = cv2.erode(img,kernel,iterations = 1) |
膨胀
与腐蚀相反,膨胀操作中只要与卷积核对应的原图像的像素值中只要有一个是 $1$,中心元素的像素值就是 $1$。所以这个操作会增加图像中的白色区域(前景)。一般在去噪声时先用腐蚀再用膨胀。因为腐蚀在去掉白噪声的同时,也会使前景对象变小。所以我们再对他进行膨胀。这时噪声已经被去除了,不会再回来了,但是前景还在并会增加。膨胀也可以用来连接两个分开的物体。
1 | #dst=cv2.dilate(src, kernel[, dst[, anchor[, iterations[, borderType[, borderValue]]]]]) |
2 | dilation = cv2.dilate(img,kernel,iterations = 1) |
- $src$:源图,通道数任意,深度需为$CV_8U$,$CV_16U$,$CV_16S$,$CV_32F$或 $CV_64F$
- $dst$:输出图,与$src$有着同样的尺寸
- $kernel$:膨胀操作的核,通常这个参数由函数
cv2.getStructuringElement得到 - $anchor$:锚点位置,默认值为中心点
- $iterations$:自身迭代的次数,默认为1
- $borderType$和$borderValue$都有各自的默认值,通常不用理会
开运算
先进行腐蚀再进行膨胀就叫做开运算。就像我们上面介绍的那样,它被用来去除噪声。这里我们用到的函数是 cv2.morphologyEx()。
1 | #dst=cv2.morphologyEx(src, op, kernel[, dst[, anchor[, iterations[, borderType[,borderValue]]]]]) |
2 | opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel) |
op:操作标识符,即进行哪种操作,有下表(节选,注意将cv改为cv2):

闭运算
先膨胀再腐蚀。它经常被用来填充前景物体中的小洞,或者前景物体上的小黑点。
1 | closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel) |
其中开运算能够消除小物体,闭运算能够排除小黑色区域。
形态学梯度
其实就是一幅图像膨胀与腐蚀的差别。
结果看上去就像前景物体的轮廓。
1 | gradient = cv2.morphologyEx(img, cv2.MORPH_GRADIENT, kernel) |
礼帽
原始图像与进行开运算之后得到的图像的差。
1 | tophat = cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel) |
黑帽
进行闭运算之后得到的图像与原始图像的差。
1 | blackhat = cv2.morphologyEx(img, cv2.MORPH_BLACKHAT, kernel) |
形态学操作之间的关系

结构化元素
在前面的例子中我们使用 $Numpy$ 构建了结构化元素,它是正方形的。但有时我们需要构建一个椭圆形/圆形的核。为了实现这种要求,提供了 OpenCV 函数 cv2.getStructuringElement()。你只需要告诉他你需要的核的形状和大小。
1 | # Rectangular Kernel |
2 | cv2.getStructuringElement(cv2.MORPH_RECT,(5,5)) |
3 | array([[1, 1, 1, 1, 1], |
4 | [1, 1, 1, 1, 1], |
5 | [1, 1, 1, 1, 1], |
6 | [1, 1, 1, 1, 1], |
7 | [1, 1, 1, 1, 1]], dtype=uint8) |
8 | # Elliptical Kernel |
9 | cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(5,5)) |
10 | array([[0, 0, 1, 0, 0], |
11 | [1, 1, 1, 1, 1], |
12 | [1, 1, 1, 1, 1], |
13 | [1, 1, 1, 1, 1], |
14 | [0, 0, 1, 0, 0]], dtype=uint8) |
15 | # Cross-shaped Kernel |
16 | cv2.getStructuringElement(cv2.MORPH_CROSS,(5,5)) |
17 | array([[0, 0, 1, 0, 0], |
18 | [0, 0, 1, 0, 0], |
19 | [1, 1, 1, 1, 1], |
20 | [0, 0, 1, 0, 0], |
21 | [0, 0, 1, 0, 0]], dtype=uint8) |
图像梯度
梯度简单来说就是求导。
OpenCV 提供了三种不同的梯度滤波器,或者说高通滤波器:$Sobel$, $Scharr$ 和 $Laplacian$。我们会一一介绍他们。
$Sobel$,$Scharr$ 其实就是求一阶或二阶导数。$Scharr$ 是对 $Sobel$(使用小的卷积核求解求解梯度角度时)的优化。$Laplacian$ 是求二阶导数。
$Sobel$ 算子和 $Scharr$ 算子
$Sobel$ 算子是高斯平滑与微分操作的结合体,所以它的抗噪声能力很好。 你可以设定求导的方向($xorder$ 或 $yorder$)。还可以设定使用的卷积核的大 小($ksize$)。如果 $ksize=-1$,会使用 $3 3$ 的 $Scharr$ 滤波器,它的的效果要 比 $3 3$ 的 $Sobel$ 滤波器好(而且速度相同,所以在使用 $ 33 $ 滤波器时应该尽量使用 $Scharr$ 滤波器)。 $33$ 的 $Scharr$ 滤波器卷积核如下:
$Laplacian$ 算子
拉普拉斯算子可以使用二阶导数的形式定义,可假设其离散实现类似于二阶 $Sobel$ 导数,事实上,$OpenCV$ 在计算拉普拉斯算子时直接调用 $Sobel$ 算 子。计算公式如下:
拉普拉斯滤波器使用的卷积核:
下面的代码分别使用以上三种滤波器对同一幅图进行操作。使用的卷积核都是 $5 * 5$ 的。
1 | import cv2 |
2 | import numpy as np |
3 | from matplotlib import pyplot as plt |
4 | img=cv2.imread('dave.jpg',0) |
5 | #cv2.CV_64F 输出图像的深度(数据类型),可以使用-1, 与原图像保持一致 np.uint8 |
6 | laplacian=cv2.Laplacian(img,cv2.CV_64F) |
7 | # 参数 1,0 为只在 x 方向求一阶导数,最大可以求 2 阶导数。 |
8 | sobelx=cv2.Sobel(img,cv2.CV_64F,1,0,ksize=5) |
9 | # 参数 0,1 为只在 y 方向求一阶导数,最大可以求 2 阶导数。 |
10 | sobely=cv2.Sobel(img,cv2.CV_64F,0,1,ksize=5) |
11 | plt.subplot(2,2,1),plt.imshow(img,cmap = 'gray') |
12 | plt.title('Original'), plt.xticks([]), plt.yticks([]) |
13 | plt.subplot(2,2,2),plt.imshow(laplacian,cmap = 'gray') |
14 | plt.title('Laplacian'), plt.xticks([]), plt.yticks([]) |
15 | plt.subplot(2,2,3),plt.imshow(sobelx,cmap = 'gray') |
16 | plt.title('Sobel X'), plt.xticks([]), plt.yticks([]) |
17 | plt.subplot(2,2,4),plt.imshow(sobely,cmap = 'gray') |
18 | plt.title('Sobel Y'), plt.xticks([]), plt.yticks([]) |
19 | plt.show() |
注意:
在查看上面这个例子的注释时不知道你有没有注意到:我们可以通过参数 $-1$ 来设定输出图像的深度(数据类型)与原图像保持一致,但是我们在代码中使用的却是 $cv2.CV_64F$。这是为什么呢?想象一下一个从黑到白的边界的导数是整数,而一个从白到黑的边界点导数却是负数。如果原图像的深度是 $np.int8$ 时,所有的负值都会被截断变成 $0$,换句话说就是把把边界丢失掉。 所以如果这两种边界你都想检测到,最好的的办法就是将输出的数据类型 设置的更高,比如 $cv2.CV_16S$,$cv2.CV_64F$ 等。取绝对值然后再把它转回 到 $cv2.CV_8U$。下面的示例演示了输出图片的深度不同造成的不同效果。
1 | import cv2 |
2 | import numpy as np |
3 | from matplotlib import pyplot as plt |
4 | img = cv2.imread('boxs.png',0) |
5 | # Output dtype = cv2.CV_8U |
6 | sobelx8u = cv2.Sobel(img,cv2.CV_8U,1,0,ksize=5) |
7 | # 也可以将参数设为-1 |
8 | #sobelx8u = cv2.Sobel(img,-1,1,0,ksize=5) |
9 | # Output dtype = cv2.CV_64F. Then take its absolute and convert to cv2.CV_8U |
10 | sobelx64f = cv2.Sobel(img,cv2.CV_64F,1,0,ksize=5) |
11 | abs_sobel64f = np.absolute(sobelx64f) |
12 | sobel_8u = np.uint8(abs_sobel64f) |
13 | plt.subplot(1,3,1),plt.imshow(img,cmap = 'gray') |
14 | plt.title('Original'), plt.xticks([]), plt.yticks([]) |
15 | plt.subplot(1,3,2),plt.imshow(sobelx8u,cmap = 'gray') |
16 | plt.title('Sobel CV_8U'), plt.xticks([]), plt.yticks([]) |
17 | plt.subplot(1,3,3),plt.imshow(sobel_8u,cmap = 'gray') |
18 | plt.title('Sobel abs(CV_64F)'), plt.xticks([]), plt.yticks([]) |
19 | plt.show() |
Canny边缘检测
$Canny$ 边缘检测是一种非常流行的边缘检测算法,是 John F.Canny 在 1986 年提出的。它是一个有很多步构成的算法,我们接下来会逐步介绍。
噪声去除
由于边缘检测很容易受到噪声影响,所以第一步是使用 $ 5 * 5 $ 的高斯滤波器去除噪声
计算图像梯度
对平滑后的图像使用 $Sobel$ 算子计算水平方向和竖直方向的一阶导数(图像梯度)($Gx$ 和 $Gy$)。根据得到的这两幅梯度图($Gx$ 和 $Gy$)找到边界的梯度和方向,公式如下:
梯度的方向一般总是与边界垂直。梯度方向被归为四类:垂直,水平,和两个对角线。
非极大值抑制
在获得梯度的方向和大小之后,应该对整幅图像做一个扫描,去除那些非 边界上的点。对每一个像素进行检查,看这个点的梯度是不是周围具有相同梯度方向的点中最大的。如下图所示:
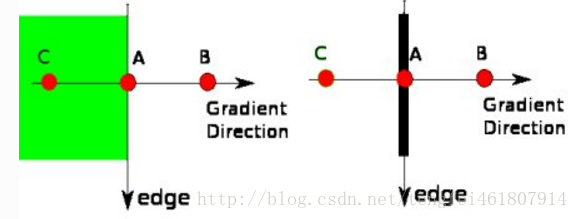
$A$点在边界上(垂直方向),梯度方向是边界的法向量。点$B$和点$C$在梯度方向上面,所以点$A$检测点$B$和$C$是否形成了本地最大值,如果形成最大值,那么就进行下一步,否则进行抑制(赋值为0)
简单的说,现在得到的是一个包含“窄边界”的二值图像。
滞后阈值
现在要确定那些边界才是真正的边界。这时我们需要设置两个阈值: $minVal$ 和 $maxVal$。当图像的灰度梯度高于 $maxVal$ 时被认为是真的边界, 那些低于 $minVal$ 的边界会被抛弃。如果介于两者之间的话,就要看这个点是 否与某个被确定为真正的边界点相连,如果是就认为它也是边界点,如果不是就抛弃。如下图:

$A$ 高于阈值 $maxVal$ 所以是真正的边界点,$C$ 虽然低于 $maxVal$ 但高于 $minVal$ 并且与 A 相连,所以也被认为是真正的边界点。而 $B$ 就会被抛弃,因 为他不仅低于 $maxVal$ 而且不与真正的边界点相连。所以选择合适的 $maxVal$ 和 $minVal$ 对于能否得到好的结果非常重要。 在这一步一些小的噪声点也会被除去,因为我们假设边界都是一些长的线段。
实现:
1 | import cv2 |
2 | import numpy as np |
3 | |
4 | m1 = np.array([[-1,0,1],[-1,0,1],[-1,0,1]]) |
5 | m2 = np.array([[-1,-1,-1],[0,0,0],[1,1,1]]) |
6 | from matplotlib import pyplot as plt |
7 | # 第一步:完成高斯平滑滤波 |
8 | img = cv2.imread("rice.jpg",0) |
9 | img = cv2.GaussianBlur(img,(3,3),2) |
10 | |
11 | # 第二步:完成一阶有限差分计算,计算每一点的梯度幅值与方向 |
12 | img1 = np.zeros(img.shape,dtype="uint8") # 与原图大小相同 |
13 | theta = np.zeros(img.shape,dtype="float") # 方向矩阵原图像大小 |
14 | img = cv2.copyMakeBorder(img,1,1,1,1,borderType=cv2.BORDER_REPLICATE) |
15 | rows,cols = img.shape |
16 | for i in range(1,rows-1): |
17 | for j in range(1,cols-1): |
18 | # Gy |
19 | Gy = (np.dot(np.array([1, 1, 1]), (m1 * img[i - 1:i + 2, j - 1:j + 2]))).dot(np.array([[1], [1], [1]])) |
20 | # Gx |
21 | Gx = (np.dot(np.array([1, 1, 1]), (m2 * img[i - 1:i + 2, j - 1:j + 2]))).dot(np.array([[1], [1], [1]])) |
22 | if Gx[0] == 0: |
23 | theta[i-1,j-1] = 90 |
24 | continue |
25 | else: |
26 | temp = (np.arctan(Gy[0] / Gx[0]) ) * 180 / np.pi |
27 | if Gx[0]*Gy[0] > 0: |
28 | if Gx[0] > 0: |
29 | theta[i-1,j-1] = np.abs(temp) |
30 | else: |
31 | theta[i-1,j-1] = (np.abs(temp) - 180) |
32 | if Gx[0] * Gy[0] < 0: |
33 | if Gx[0] > 0: |
34 | theta[i-1,j-1] = (-1) * np.abs(temp) |
35 | else: |
36 | theta[i-1,j-1] = 180 - np.abs(temp) |
37 | img1[i-1,j-1] = (np.sqrt(Gx**2 + Gy**2)) |
38 | for i in range(1,rows - 2): |
39 | for j in range(1, cols - 2): |
40 | if ( ( (theta[i,j] >= -22.5) and (theta[i,j]< 22.5) ) or |
41 | ( (theta[i,j] <= -157.5) and (theta[i,j] >= -180) ) or |
42 | ( (theta[i,j] >= 157.5) and (theta[i,j] < 180) ) ): |
43 | theta[i,j] = 0.0 |
44 | elif ( ( (theta[i,j] >= 22.5) and (theta[i,j]< 67.5) ) or |
45 | ( (theta[i,j] <= -112.5) and (theta[i,j] >= -157.5) ) ): |
46 | theta[i,j] = 45.0 |
47 | elif ( ( (theta[i,j] >= 67.5) and (theta[i,j]< 112.5) ) or |
48 | ( (theta[i,j] <= -67.5) and (theta[i,j] >= -112.5) ) ): |
49 | theta[i,j] = 90.0 |
50 | elif ( ( (theta[i,j] >= 112.5) and (theta[i,j]< 157.5) ) or |
51 | ( (theta[i,j] <= -22.5) and (theta[i,j] >= -67.5) ) ): |
52 | theta[i,j] = -45.0 |
53 | |
54 | # 第三步:进行 非极大值抑制计算 |
55 | img2 = np.zeros(img1.shape) # 非极大值抑制图像矩阵 |
56 | |
57 | for i in range(1,img2.shape[0]-1): |
58 | for j in range(1,img2.shape[1]-1): |
59 | if (theta[i,j] == 0.0) and (img1[i,j] == np.max([img1[i,j],img1[i+1,j],img1[i-1,j]]) ): |
60 | img2[i,j] = img1[i,j] |
61 | |
62 | if (theta[i,j] == -45.0) and img1[i,j] == np.max([img1[i,j],img1[i-1,j-1],img1[i+1,j+1]]): |
63 | img2[i,j] = img1[i,j] |
64 | |
65 | if (theta[i,j] == 90.0) and img1[i,j] == np.max([img1[i,j],img1[i,j+1],img1[i,j-1]]): |
66 | img2[i,j] = img1[i,j] |
67 | |
68 | if (theta[i,j] == 45.0) and img1[i,j] == np.max([img1[i,j],img1[i-1,j+1],img1[i+1,j-1]]): |
69 | img2[i,j] = img1[i,j] |
70 | |
71 | # 第四步:双阈值检测和边缘连接 |
72 | img3 = np.zeros(img2.shape) #定义双阈值图像 |
73 | # TL = 0.4*np.max(img2) |
74 | # TH = 0.5*np.max(img2) |
75 | TL = 50 |
76 | TH = 100 |
77 | #关键在这两个阈值的选择 |
78 | for i in range(1,img3.shape[0]-1): |
79 | for j in range(1,img3.shape[1]-1): |
80 | if img2[i,j] < TL: |
81 | img3[i,j] = 0 |
82 | elif img2[i,j] > TH: |
83 | img3[i,j] = 255 |
84 | elif (( img2[i+1,j] < TH) or (img2[i-1,j] < TH )or( img2[i,j+1] < TH )or |
85 | (img2[i,j-1] < TH) or (img2[i-1, j-1] < TH )or ( img2[i-1, j+1] < TH) or |
86 | ( img2[i+1, j+1] < TH ) or ( img2[i+1, j-1] < TH) ): |
87 | img3[i,j] = 255 |
88 | |
89 | |
90 | cv2.imshow("1",img) # 原始图像 |
91 | cv2.imshow("2",img1) # 梯度幅值图 |
92 | cv2.imshow("3",img2) #非极大值抑制灰度图 |
93 | cv2.imshow("4",img3) # 最终效果图 |
94 | cv2.imshow("theta",theta) #角度值灰度图 |
95 | cv2.waitKey(0) |
96 | ———————————————— |
97 | 版权声明:本文为CSDN博主「飘云之下」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。 |
98 | 原文链接:https://blog.csdn.net/weixin_44403952/article/details/90375013 |
OpenCV 中的 Canny 边界检测
在 OpenCV 中只需要一个函数:cv2.Canny(),就可以完成以上几步。 让我们看如何使用这个函数。这个函数的第一个参数是输入图像。第二和第三个分别是 $minVal$ 和 $maxVal$。第三个参数设置用来计算图像梯度的 $Sobel$ 卷积核的大小,默认值为 $3$。最后一个参数是 $L2gradient$,它可以用来设定 求梯度大小的方程。如果设为 $True$,就会使用我们上面提到过的方程,否则使用方程:$Edge_Gradient(G) = |G^2_x | + |G^2_y | $代替,默认值为 $False$。
1 | import cv2 |
2 | import numpy as np |
3 | img = cv2.imread("material/dlam.jpg",0) |
4 | res = cv2.Canny(img,100,200) |
5 | res = np.hstack((img,res)) |
6 | cv2.imshow("image",res) |
7 | cv2.imwrite("canny.png",res) |
8 | cv2.waitKey(0) |
9 | cv2.destroyAllWindows() |

图像金字塔
原理
一般情况下,我们要处理是一副具有固定分辨率的图像。但是有些情况下, 我们需要对同一图像的不同分辨率的子图像进行处理。比如,我们要在一幅图像中查找某个目标,比如脸,我们不知道目标在图像中的尺寸大小。这种情况下,我们需要创建创建一组图像,这些图像是具有不同分辨率的原始图像。我们把这组图像叫做图像金字塔(简单来说就是同一图像的不同分辨率的子图集合)。如果我们把最大的图像放在底部,最小的放在顶部,看起来像一座金字塔,故而得名图像金字塔。
有两类图像金字塔:高斯金字塔和拉普拉斯金字塔。高斯金字塔的顶部是通过将底部图像中的连续的行和列去除得到的。顶部图像中的每个像素值等于下面一层图像中 5 个像素的高斯加权平均值。这样操作一次一个 $M N$ 的图像就变成了一个 $\frac{M}{2}\frac{N}{2}$ 的图像。所以这幅图像的面积就变为原来图像面积的四分之一。这被称为 $Octave$。连续进行这样的操作我们就会得到一个分辨率不断下降的图像金字塔。我们可以使用函数 cv2.pyrDown() 和 cv2.pyrUp() 构建图像金字塔。 函数 cv2.pyrDown() 从一个高分辨率大尺寸的图像向上构建一个金子塔 (尺寸变小,分辨率降低),即一旦使用 cv2.pyrDown(),图像的分辨率就会降低,信息就会被丢失。
对图像的向下取样操作,即缩小图像,方法步骤如下:
对图像G_i进行高斯内核卷积,进行高斯模糊;
将所有偶数行和列去除。
对图像的向上取样,即放大图像,方法步骤如下:
将图像在每个方向扩大为原来的两倍,新增的行和列以0填充
使用先前同样的内核(乘以4)与放大后的图像卷积,获得 “新增像素”的近似值
拉普拉斯金字塔可以有高斯金字塔计算得来,公式如下:
拉普拉金字塔的图像看起来就像边界图,其中很多像素都是 0。他们经常被用在图像压缩中。
使用金字塔进行图像融合
图像金字塔的一个应用是图像融合。例如,在图像缝合中,你需要将两幅图叠在一起,但是由于连接区域图像像素的不连续性,整幅图的效果看起来会很差。这时图像金字塔就可以排上用场了,他可以帮你实现无缝连接。
1 | import cv2 |
2 | import numpy as np |
3 | img1 = cv2.imread("material/s3.jfif") |
4 | img2 = cv2.imread("material/s2.jfif") |
5 | h,w,d = img2.shape |
6 | print(h,w) |
7 | img1 = cv2.resize(img1,(w,h),cv2.INTER_AREA) |
8 | G = img1.copy() |
9 | gpa = [G] |
10 | for i in range(6): |
11 | G = cv2.pyrDown(G) |
12 | gpa.append(G) |
13 | G = img2.copy() |
14 | gpb = [G] |
15 | for i in range(6): |
16 | G = cv2.pyrDown(G) |
17 | gpb.append(G) |
18 | lpa = [gpa[5]] |
19 | for i in range(5,0,-1): |
20 | GE = cv2.pyrUp(gpa[i]) |
21 | L = cv2.subtract(gpa[i-1],GE) |
22 | lpa.append(L) |
23 | lpb = [gpb[5]] |
24 | for i in range(5,0,-1): |
25 | GE = cv2.pyrUp(gpb[i]) |
26 | L = cv2.subtract(gpb[i-1],GE) |
27 | lpb.append(L) |
28 | LS = [] |
29 | for la,lb in zip(lpa,lpb): |
30 | h,w,d = la.shape |
31 | ls = np.vstack((la[0:h//2,:],lb[h//2:,:])) |
32 | LS.append(ls) |
33 | ls = LS[0] |
34 | for i in range(1,6): |
35 | ls = cv2.pyrUp(ls) |
36 | ls = cv2.add(ls,LS[i]) |
37 | h,w,d = img1.shape |
38 | real = np.vstack((img1[:h//2,:],img2[h//2:,:])) |
39 | cv2.imshow("real",real) |
40 | cv2.imshow("merge",ls) |
41 | cv2.imwrite("real.jpg",real) |
42 | cv2.imwrite("blending.jpg",ls) |
43 | cv2.waitKey(0) |
44 | cv2.destroyAllWindows() |

OpenCV 中的轮廓
什么是轮廓
轮廓可以简单认为成将连续的点(连着边界)连在一起的曲线,具有相同的颜色或者灰度。轮廓在形状分析和物体的检测和识别中很有用。
- 为了更加准确,要使用二值化图像。在寻找轮廓之前,要进行阈值化处理或者 Canny 边界检测。
- 查找轮廓的函数会修改原始图像。如果你在找到轮廓之后还想使用原始图像的话,你应该将原始图像存储到其他变量中。
- 在 OpenCV 中,查找轮廓就像在黑色背景中找白色物体。你应该记住, 要找的物体应该是白色而背景应该是黑色。
让我们看看如何在一个二值图像中查找轮廓:
函数 cv2.findContours() 有三个参数,第一个是输入图像,第二个是轮廓检索模式,第三个是轮廓近似方法。返回值有三个,第一个是图像,第二个是轮廓,第三个是(轮廓的)层析结构。轮廓(第二个返回值)是一个 Python 列表,其中存储这图像中的所有轮廓。每一个轮廓都是一个 $Numpy$ 数组,包含对象边界点$(x,y)$的坐标。
注意:我们后边会对第二和第三个参数,以及层次结构进行详细介绍。在那之前,例子中使用的参数值对所有图像都是适用的。
怎样绘制轮廓
函数 cv2.drawContours() 可以被用来绘制轮廓。它可以根据你提供的边界点绘制任何形状。它的第一个参数是原始图像,第二个参数是轮廓,一个 $Python$ 列表。第三个参数是轮廓的索引(在绘制独立轮廓是很有用,当设置为 $-1$ 时绘制所有轮廓)。接下来的参数是轮廓的颜色和厚度等。
1 | import numpy as np |
2 | import cv2 |
3 | im = cv2.imread('material/bk.jpg') |
4 | imgray = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY) |
5 | ret,thresh = cv2.threshold(imgray,127,255,0) |
6 | contours, hierarchy = cv2.findContours(thresh,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE) |
7 | bi = np.zeros(im.shape,np.uint8) |
8 | imag = cv2.drawContours(bi,contours,-1,(255,255,255),3) |
9 | cv2.imshow("image",imag) |
10 | cv2.waitKey(0) |
11 | cv2.destroyAllWindows() |
轮廓的近似方法
这是函数 cv2.findCountours() 的第三个参数。它到底代表什么意思呢?
上边我们已经提到轮廓是一个形状具有相同灰度值的边界。它会存贮形状边界上所有的 $(x,y)$ 坐标。但是需要将所有的这些边界点都存储吗?这就是这个参数要告诉函数 cv2.findContours 的。 这个参数如果被设置为 cv2.CHAIN_APPROX_NONE,所有的边界点都会被存储。但当我们找的边界是一条直线时,我们只需要这条直线的两个端点。这就是 cv2.CHAIN_APPROX_SIMPLE 要做的。它会将轮廓上的冗余点都去掉,压缩轮廓,从而节省内存开支。
轮廓特征
矩
图像的矩可以帮助我们计算图像的质心,面积等
函数 cv2.moments() 会将计算得到的矩以一个字典的形式返回。如下:
1 | import cv2 |
2 | import numpy as np |
3 | img = cv2.imread('star.jpg',0) |
4 | ret,thresh = cv2.threshold(img,127,255,0) |
5 | contours,hierarchy = cv2.findContours(thresh, 1, 2) |
6 | cnt = contours[0] |
7 | M = cv2.moments(cnt) |
8 | print(M) |
根据这些矩的值,我们可以计算出对象的重:$C_x = \frac{M_{10}}{M_{00}} ,Cy = \frac{M_{01}}{M_{00}}$ 。
1 | cx = int(M['m10']/M['m00']) |
2 | cy = int(M['m01']/M['m00']) |
轮廓面积
轮廓的面积可以使用函数 cv2.contourArea() 计算得到,也可以使用矩 ( $0$ 阶矩),$M[‘m00’]$。
1 | area = cv2.contourArea(cnt) |
轮廓周长
也被称为弧长。可以使用函数 cv2.arcLength() 计算得到。这个函数的第二参数可以用来指定对象的形状是闭合的$(True)$,还是打开的(一条曲线)。
1 | perimeter = cv2.arcLength(cnt,True) |
轮廓近似
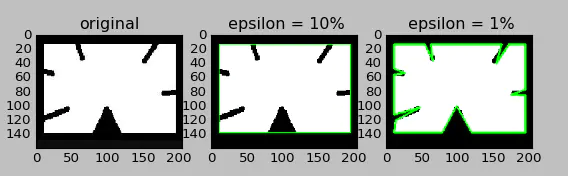
将轮廓形状近似到另外一种由更少点组成的轮廓形状,新轮廓的点的数目由我们设定的准确度来决定。使用的$Douglas-Peucker$算法。 为了帮助理解,假设我们要在一幅图像中查找一个矩形,但是由于图像的种种原因,我们不能得到一个完美的矩形,而是一个“坏形状”。 现在就可以使用这个函数来近似这个形状了。这个函数的第二个参数叫 $epsilon$,它是从原始轮廓到近似轮廓的最大距离。它是一个准确度参数。选择一个好的 $epsilon$ 对于得到满意结果非常重要;第三个参数设定弧线是否闭合。
1 | epsilon=0.1*cv2.arcLength(cnt,True) |
2 | approx= cv2.approxPolyDP(cnt,epsilon,True) |
3 | temp = cv2.cvtColor(image.copy(), cv2.COLOR_GRAY2BGR) |
4 | cv2.drawContours(temp, [approx], -1, (0, 255, 0), 2) |
5 | epsilon2=0.01*cv2.arcLength(cnt,True) |
6 | approx2= cv2.approxPolyDP(cnt,epsilon2,True) |
7 | temp2 = cv2.cvtColor(image.copy(), cv2.COLOR_GRAY2BGR) |
8 | cv2.drawContours(temp2, [approx2], -1, (0, 255, 0), 2) |
9 | plt.subplot(231),plt.imshow(img,'gray'),plt.title('original') |
10 | plt.subplot(232),plt.imshow(temp,'gray'),plt.title(' epsilon = 10%') |
11 | plt.subplot(233),plt.imshow(temp2,'gray'),plt.title(' epsilon = 1%') |
12 | plt.show() |
13 | |
14 | 作者:Zoe_C |
15 | 链接:https://www.jianshu.com/p/2b60802306a8 |
16 | 来源:简书 |
凸包
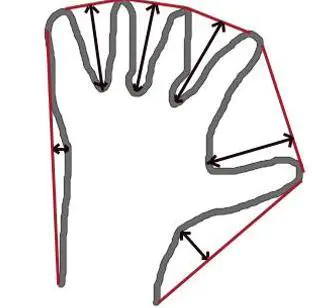
凸包与轮廓近似相似,但不同,虽然有些情况下它们给出的结果是一样的。 函数 cv2.convexHull() 可以用来检测一个曲线是否具有凸性缺陷,并能纠正缺陷。一般来说,凸性曲线总是凸出来的,至少是平的。如果有地方凹进去就被叫做凸性缺陷。例如下图中的手。红色曲线显示了手的凸包,凸性缺陷被双箭头标出来了。
关于他的语法还有一些需要交代:
1 | hull = cv2.convexHull(points[, hull[, clockwise[, returnPoints]] |
参数:
- $points$ 我们要传入的轮廓
- $hull$ 输出,通常不需要
- $clockwise$ 方向标志。如果设置为 $True$,输出的凸包是顺时针方向的。 否则为逆时针方向。
- $returnPoints$ 默认值为 $True$。它会返回凸包上点的坐标。如果设置为 $False$,就会返回与凸包点对应的轮廓上的点。
要获得上图的凸包,下面的命令就够了:
1 | hull = cv2.convexHull(cnt) |
但是如果你想获得凸性缺陷,需要把 $returnPoints$ 设置为 $False$。以 上面的矩形为例,首先我们找到他的轮廓 $cnt$。现在我把 $returnPoints$ 设置 为 True 查找凸包,我得到下列值:
$[[[234 \space 202]], [[ 51 \space 202]], [[ 51 \space 79]], [[234 \space 79]]]$,其实就是矩形的四个角点。
现在把 $returnPoints$ 设置为 $False$,得到的结果是 $[[129],[ 67],[ 0],[142]]$
他们是轮廓点的索引。例如:$cnt[129] = [[234, 202]]$,这与前面我们得到结果的第一个值是一样的。 在凸检验中还会遇到这些。
凸性检测
函数 cv2.isContourConvex()可以可以用来检测一个曲线是不是凸的。它只能返回 $True$ 或 $False$。没什么大不了的。
1 | k = cv2.isContourConvex(cnt) |
边界矩形
有两类边界矩形。
直边界矩形 一个直矩形(就是没有旋转的矩形)。它不会考虑对象是否旋转。所以边界矩形的面积不是最小的。可以使用函数cv2.boundingRect() 查找得到。
$(x,y)$为矩形左上角的坐标,$(w,h)$是矩形的宽和高。
1 | x,y,w,h = cv2.boundingRect(cnt) |
2 | img = cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,0),2) |
旋转的边界矩形 这个边界矩形是面积最小的,因为它考虑了对象的旋转。用的函数为cv2.minAreaRect()。返回的是一个$Box2D$ 结构,其中包含矩形左上角角点的坐标$(x,y)$,矩形的宽和高$(w,h)$,以及旋转角度。但是要绘制这个矩形需要矩形的 $4$ 个角点,可以通过函数cv2.boxPoints() 获得。
1 | rect = cv2.minAreaRect(cnt)#计算最小矩形区域 |
2 | box = cv2.boxPoints(rect) |
3 | box = np.int0(box)#浮点型转为整形 |
4 | cv2.drawContours(im, [box], 0, (0,0,255), 3) |
把这两中边界矩形显示在下图中,其中绿色的为直矩形,红的为旋转矩形。

最小外接圆
函数cv2.minEnclosingCircle() 可以帮我们找到一个对象的外切圆。它是所有能够包括对象的圆中面积最小的一个。
1 | (x,y),radius = cv2.minEnclosingCircle(cnt) |
2 | center = (int(x),int(y)) |
3 | radius = int(radius) |
4 | img = cv2.circle(img,center,radius,(0,255,0),2) |

椭圆拟合
使用的函数为cv2.fitEllipse(),返回值其实就是旋转边界矩形的内切圆
1 | ellipse = cv2.fitEllipse(cnt) |
2 | im = cv2.ellipse(im,ellipse,(0,255,0),2) |
直线拟合
我们可以根据一组点拟合出一条直线,同样我们也可以为图像中的白色点拟合出一条直线。
1 | rows,cols = img.shape[:2] |
2 | #cv2.fitLine(points, distType, param, reps, aeps[, line ]) → line |
3 | #points – Input vector of 2D or 3D points, stored in std::vector<> or Mat. |
4 | #line – Output line parameters. In case of 2D fitting, it should be a vector of |
5 | #4 elements (likeVec4f) - (vx, vy, x0, y0), where (vx, vy) is a normalized |
6 | #vector collinear to the line and (x0, y0) is a point on the line. In case of |
7 | #3D fitting, it should be a vector of 6 elements (like Vec6f) - (vx, vy, vz, |
8 | #x0, y0, z0), where (vx, vy, vz) is a normalized vector collinear to the line |
9 | #and (x0, y0, z0) is a point on the line. |
10 | #distType – Distance used by the M-estimator |
11 | #distType=CV_DIST_L2 |
12 | #ρ(r) = r2 /2 (the simplest and the fastest least-squares method) |
13 | #param – Numerical parameter ( C ) for some types of distances. If it is 0, an optimal value |
14 | #is chosen. |
15 | #reps – Sufficient accuracy for the radius (distance between the coordinate origin and the |
16 | #line). |
17 | #aeps – Sufficient accuracy for the angle. 0.01 would be a good default value for reps and |
18 | #aeps. |
19 | [vx,vy,x,y] = cv2.fitLine(cnt, cv2.DIST_L2,0,0.01,0.01) |
20 | lefty = int((-x*vy/vx) + y) |
21 | righty = int(((cols-x)*vy/vx)+y) |
22 | img = cv2.line(img,(cols-1,righty),(0,lefty),(0,255,0),2) |

轮廓的性质
长宽比
边界矩形的宽高比
1 | x,y,w,h = cv2.boundingRect(cnt) |
2 | aspect_ratio = float(w)/h |
Extent
轮廓面积与边界矩形面积的比。
1 | area = cv2.contourArea(cnt) |
2 | x,y,w,h = cv2.boundingRect(cnt) |
3 | rect_area = w*h |
4 | extent = float(area)/rect_area |
Solidity
轮廓面积与凸包面积的比。
1 | area = cv2.contourArea(cnt) |
2 | hull = cv2.convexHull(cnt) |
3 | hull_area = cv2.contourArea(hull) |
4 | solidity = float(area)/hull_area |
Equivalent Diameter
与轮廓面积相等的圆形的直径。
1 | area = cv2.contourArea(cnt) |
2 | equi_diameter = np.sqrt(4*area/np.pi) |
方向
对象的方向,下面的方法还会返回长轴和短轴的长度
1 | (x,y),(MA,ma),angle = cv2.fitEllipse(cnt) |
掩模和像素点
有时我们需要构成对象的所有像素点,我们可以这样做:
1 | mask = np.zeros(imgray.shape,np.uint8) |
2 | # 这里一定要使用参数-1, 绘制填充的的轮廓 |
3 | cv2.drawContours(mask,[cnt],0,255,-1) |
4 | #Returns a tuple of arrays, one for each dimension of a, |
5 | #containing the indices of the non-zero elements in that dimension. |
6 | #The result of this is always a 2-D array, with a row for |
7 | #each non-zero element. |
8 | #To group the indices by element, rather than dimension, use: |
9 | #transpose(nonzero(a)) |
10 | #>>> x = np.eye(3) |
11 | #>>> x |
12 | #array([[ 1., 0., 0.], |
13 | # [ 0., 1., 0.], |
14 | # [ 0., 0., 1.]]) |
15 | #>>> np.nonzero(x) |
16 | #(array([0, 1, 2]), array([0, 1, 2])) |
17 | #>>> x[np.nonzero(x)] |
18 | #array([ 1., 1., 1.]) |
19 | #>>> np.transpose(np.nonzero(x)) |
20 | #array([[0, 0], |
21 | # [1, 1], |
22 | # [2, 2]]) |
23 | pixelpoints = np.transpose(np.nonzero(mask)) |
24 | #pixelpoints = cv2.findNonZero(mask) |
这里我们是用来两种方法,第一种方法使用了$Numpy$ 函数,第二种使用了$OpenCV$ 函数。结果相同,但还是有点不同。$Numpy$ 给出的坐标是$(row,column)$形式的。而OpenCV 给出的格式是$(x,y)$形式的。所以这两个结果基本是可以互换的。$row=x,column=y$。
最大值和最小值及它们的位置
我们可以使用掩模图像得到这些参数。
1 | min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(imgray,mask = mask) |
平均颜色及平均灰度
我们也可以使用相同的掩模求一个对象的平均颜色或平均灰度。
1 | mean_val = cv2.mean(im,mask = mask) |
极点
一个对象最上面,最下面,最左边,最右边的点。
1 | leftmost = tuple(cnt[cnt[:,:,0].argmin()][0]) |
2 | rightmost = tuple(cnt[cnt[:,:,0].argmax()][0]) |
3 | topmost = tuple(cnt[cnt[:,:,1].argmin()][0]) |
4 | bottommost = tuple(cnt[cnt[:,:,1].argmax()][0]) |